
原作:Abhishek Sharma栗子野 编译整理量子位 出品 | 公众号 QbitAI
最近,HackerEarth举办的一项初学者深度学习挑战赛,落幕了。
比赛内容是,识别野生动物。
来自印度的本科生Abhishek Sharma登上了冠军宝座。
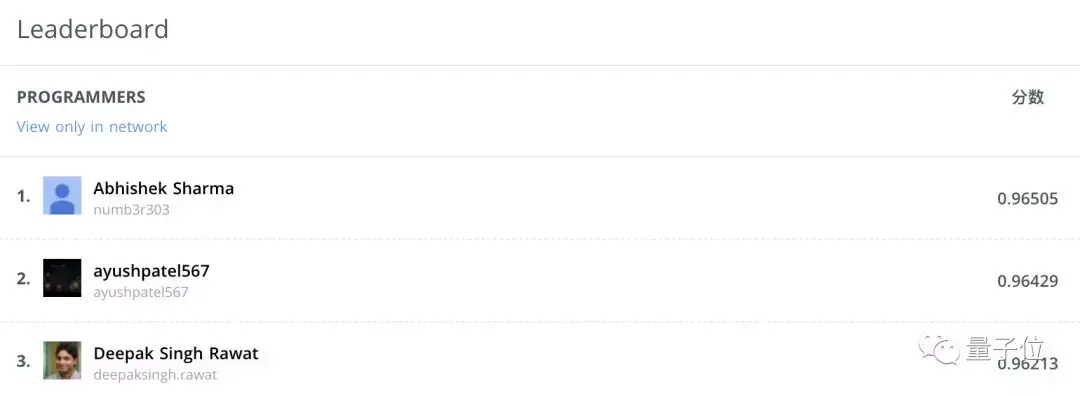
于是,他写了写自己的心得,给小伙伴们参考:
怎样的挑战
比赛数据集里有19,000张图,包含30个不同物种的野生动物。

动物的照片是在真实场景里拍摄的,姿势不同,背景复杂,光线、天气条件、视角、遮挡情况也不同。
比起这些容易造成混淆的因素,有些不同的物种,看上去并没有那么大的差别。
哪个类别的预测概率最高,图像就分给哪个物种。
评估指标:分类器的logloss。
怎样上手
拿到任务之后,要做的第一件事就是去看,以前有没有类似的问题,前人方法能不能借鉴。
少年发现,比赛数据集和ImageNet有不少交集。

那么,怎样利用它们之间的异同来改进现有的方法?
首先,本次任务里的未知 (Unknown) ,和ImageNet是非常相似的。
所以,可以用迁移学习,拿CNN做初始化或者做固定特征提取器。
迁移学习论文:https://ift.tt/2fl399G
一个区别在于图像尺寸,ImageNet里面的图像都是224 x 224像素,而动物识别任务里,图像要更大一些。
因此,要改进算法来处理大图。
熟悉问题之后,就先搭建一个简单的pipeline:从加载数据集,到训练,到验证。可以迭代几次。
怎样防止过拟合
19,000张图像里面,有13,000张属于训练集,余下6,000张是测试集。
数据集并不是很大,为了避免过拟合,少年做了以下几种尝试:
数据扩增
就是通过旋转、翻转、裁剪等这样简单的操作,把一幅图变成几幅。
这里,用了transforms_side_on随机旋转,翻转,还调了光。
数据扩增论文:https://ift.tt/2Q4lMls
学习率
深度学习网络里,最重要的超参数就是学习率。

程序猿用的是lr_find的方法,是fastai库里面提供的,用来找最优值。
这个方法是Leslie Smith提出的:刚开始训练的时候,学习率设得很低,然后给每个Batch的学习率做指数增长。
Smith论文在此:https://ift.tt/2taqJQP
训练用的图像尺寸是324 x 324,因为这些图像在验证集上表现比较好。
少年也尝试了不同的批尺寸 (Batch Size),试到32的时候,GPU存储到了上限。然后,他就为学习率做了相应的微调。
学习率vs批尺寸:https://ift.tt/2B499hB
扩大图像尺寸
用小图训练几个Epoch之后,就可以换大图 (450 x 450) 再持续训练几个Epoch。
这也是防止过拟合的一种不错的方式,在少年的logloss身上,产生了明显疗效。

各种模型合起来
少年训练了各种模型,比如resnet50,resnext101_64,inception_4,restnet152以及restnext101。然后,把它们给出的结果用加权平均整合到一起,就获得了榜首的高分。
哪些做法没有用
一是,受到下面这个Kaggle内核的启发,程序猿做了些图像相关的统计数据 (Image Related Statistics) 。
但是,在把各种网络结合在一起的时候,这些统计就减分了。
Kaggle Kernel传送门:https://ift.tt/2wMiDOt
二是,在瓶颈特征 (Bottleneck Features)上训练逻辑回归 (Logistic Regression) 。瓶颈特征,是进入全连接层之前,卷积层输出的最后结果。
这个方法,在Kaggle狗狗品种识别挑战赛里,效果很好,但在这里就不太行。

印度少年说,大家一定要尝试从各种不同的角度来看问题,不要放弃。
虽然奖金没多少……
HackerEarth是一个编程技能的线上评测系统,也举办过许多编程比赛。

虽然,有些比赛奖金并不丰厚。不过,据说比赛成绩好的选手可能获得名企的推荐资格。
野生动物识别挑战赛传送门:https://ift.tt/2Q7vdAG
第一名的GitHub传送门:https://ift.tt/2wO3FYm
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI· 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态

没有评论:
发表评论