
引言
近年来,随着 Amazon Echo 的蹿红,国内巨头们也纷纷开始布局智能音箱(百度 Raven 、阿里天猫精灵、腾讯听听、京东叮咚、小米 AI 音箱等等),相信不少同学都已经入手;同时,越来越多读书 APP 提供"听书"的功能,甚至出现将小说转有声小说的软件;手机里的语音助手、电脑里的 Cortana、车载导航中的"妹子们"说话越来越像真人,甚至感觉偶尔说话很有"感情"。这些应用背后都有用到了同一种技术——语音合成(TTS,Text To Speech)。
TTS 有着悠久的历史,在上个世纪就是热门课题,不过一直没有取得太大的突破。近些年,随着学者们开始将 TTS 与 Deep Learning 结合——毫无意外的——TTS 领域开始蒙眼狂奔,一次次突破 State of Art。在 TTS 与 Deep Learning 结合后的短短几年,出现了大量里程碑式的论文,如 Google 的 WaveNet、百度的 Deep Voice、Google 的 Tacotron 等等。其中,Tacotron 是迄今(2018年)在 End to End 的程度与 TTS 效果上做的最突出的模型,同时它还在"飞速"演进中。作为"飞速"的举证,Google Tacotron 主页列出了 Tacotron 的相关 Paper,我们可以看到在 2018 年六月、七月、八月每个月都有一篇新 Tacotron 的相关 Paper 发出,更新速度远超这个科普专栏。。。
鉴于 TTS 工作的悠久与复杂程度,本文将仅仅、并详细介绍上述的里程碑之一 —— 初代 Tacotron,以此见微知著,或者说管中窥豹地一探如今 TTS 的进展。
预备知识
从我的角度看,Tacotron 是一个极其复杂的模型:首先,它需要一定的领域知识(多亏它几乎 End to End 的特性,跟其他 TTS 模型相比,理解成本已经大幅降低);其次,它的模型结构非常复杂,体现在 Layer 的种类多且组合方式不直观(NLP 出身的同学可能更容易理解)。因此,这里先具体介绍其中用到的成熟模块,降低后续理解成本,对这些模块很熟悉的同学可以跳过。
Seq2Seq
在机器翻译领域有这么一种需求,即输入输出的数量不相等。比如:中文"苹果真是贵",英文译为"APPLE is really expensive",从五个字变成了四个单词。在"当我们在谈论 Deep Learning:RNN 其常见架构"中我们介绍了经典的 RNN,其输入输出数量必须是相等的。K.Cho 在"Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 2014"中提出一种方式来解决此类 Many to Many 的问题。假设此时需要将"x序列"转换为"y序列",则网络示意图如下
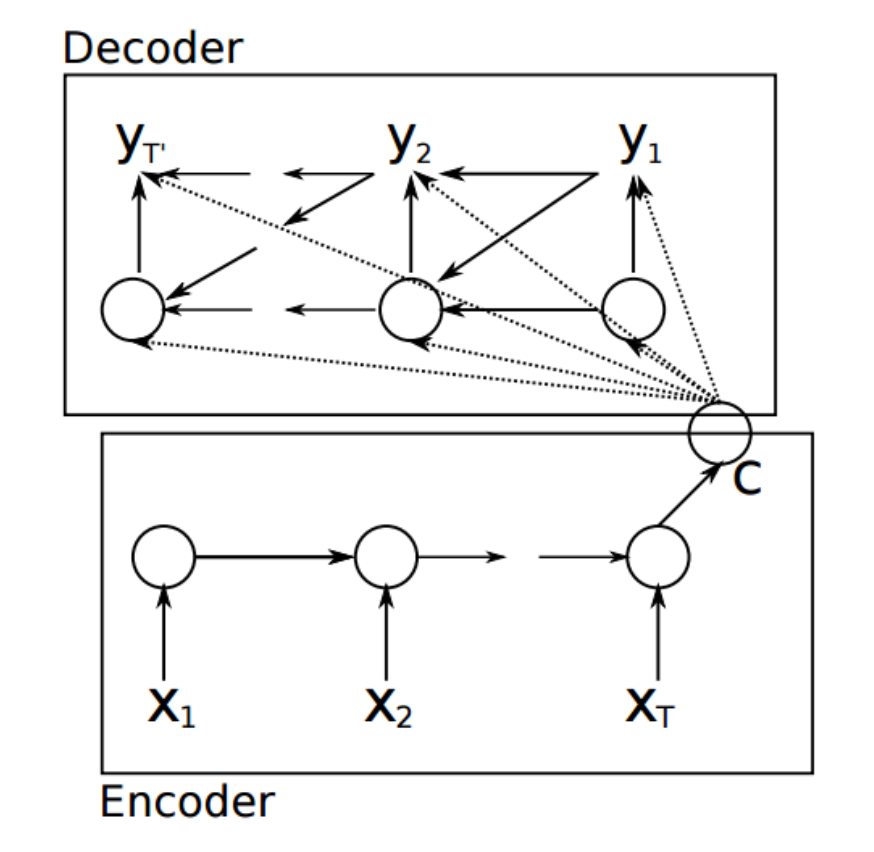
简单说来,其序列产生过程为:先将 \{(x_i, h^x_{i-1})|i=1,2...\} 依次输入给 RNN_1 ,得到隐层输出 C 。接下来依次将 \{(C, s^y_{i-1}, y_{i-1})|i=1,2...\} 输入 RNN_2 ,并期待输出 \{y_i\} 。其中, h,s 分别表示 RNN_1, RNN_2 隐层输出。
在这个模型中, RNN_1, RNN_2 分别可以被看作 Encoder,Decoder:Encoder 将 \{x_i\} 编码成隐向量 C ,再通过 Decoder 解码出输出 \{y_i\} 。此时,输出序列的长度与输入长度无关,即实现了 Many to Many 的转换。
还有另外一种相似的形式,是 Google 在"Sequence to Sequence Learning with Neural Networks. 2014"中提出的,区别仅在于此文章中 C 仅用于预测 y_1 ,后续不再使用,示意图如下
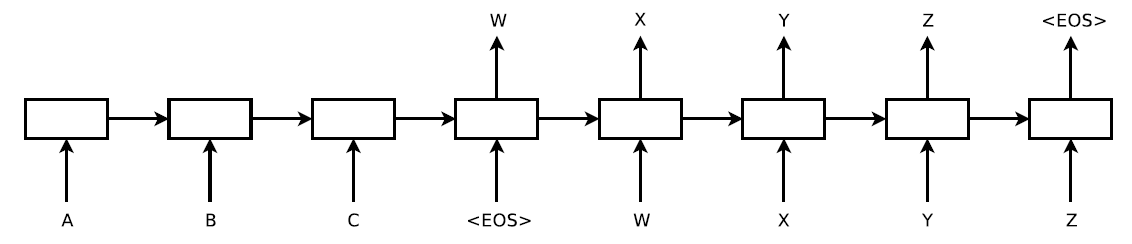
但是,上述这种 Encoder-Decoder 模型也存在问题:无论多长的输入序列,都必须编码成一个语义特征 C 用于解码,即要求 C 必须包含输入序列的完整信息,此时 C 的长度就成了此项任务最大的瓶颈。如果输入序列太长, C 长度不足则可能严重制约输出的效果。于是,Seq2Seq with Attention Model 应运而生。
Seq2Seq with Attention
Seq2Seq with Attention 最早是 Bahdanau 在"Neural Machine Translation by Jointly Learning to Align and Translate, 2014"中为了解决机器翻译中的 Align 问题提出的,其结构近似于现在大家说的 Soft Attention(因为后来各种 Attention 的方式被提出,为了区分所以有了各种命名)。
Seq2Seq with Attention 与 Seq2Seq 最大的区别就在于 Decoder,其输出
p \left( y _ { i } | y _ { 1 } , \ldots , y _ { i - 1 } , \mathbf { x } \right) = g \left( y _ { i - 1 } , s _ { i } , c _ { i } \right)
可以看出,这里关键就是 C 被替换成了 c_i 。这里 c_i 可以理解为对输入序列关注的分布,也就是输入的哪些信息对当前的输出是有意义的;而以前的 C 是对所有信息的汇总,有同学也戏称为"注意力不集中",这就是 Attention 命名的由来。Attention Model 的示意图如下
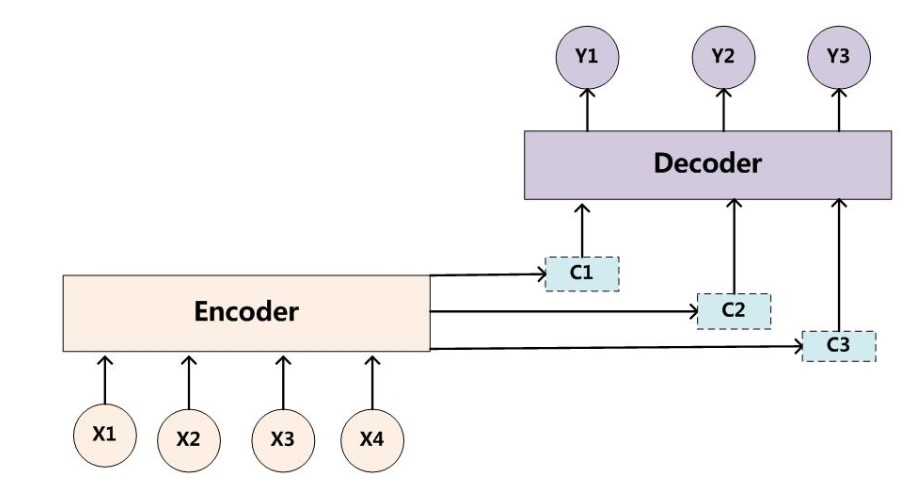
Attention Model 的完整公式如下
\begin{align} & p \left( y _ { i } | y _ { 1 } , \ldots , y _ { i - 1 } , \mathbf { x } \right) = g \left( y _ { i - 1 } , s _ { i } , c _ { i } \right) \\ & s _ { i } = f \left( s _ { i - 1 } , y _ { i - 1 } , c _ { i } \right) \\ & c _ { i } = \sum _ { j = 1 } ^ { T _ { x } } \alpha _ { i j } h _ { j } \\ & \alpha _ { i j } = \frac { \exp \left( e _ { i j } \right) } { \sum _ { k = 1 } ^ { T _ { x } } \exp \left( e _ { i k } \right) } \\ & e _ { i j } = a \left( s _ { i - 1 } , h _ { j } \right) \\ \end{align}
其中, h,s 分别表示 Encoder、Decoder 的隐状态。 h_j 被称为 annotations,包含了部分输入序列的信息,并主要是 x_j 的信息。 c_i 称为 context vector,是 h_i 的加权和,表示为了得到当前输出状态 s_i ,输入序列按照注意力 \alpha 加权提取后的结果。 \alpha_{ij} 表示为了得到 s_i ,每个 h_j 所对应的归一化后的注意力,这里使用 softmax 的方式归一,原始的权重是 e 。 e_{ij} 即为了得到 s_i ,每个 h_j 所对应的注意力,如上述公式,它跟 s _ { i - 1 } , h _ { j } 相关,具体计算可以自己定义。在本文中,作者的定义如下,并使用一个小型神经网络来优化
a \left( s _ { i - 1 } , h _ { j } \right) = v _ { a } ^ { \top } \tanh \left( W _ { a } s _ { i - 1 } + U _ { a } h _ { j } \right)
在"Approaches to Attention-based Neural Machine Translation"中,Luong 还提出了其他几种权重计算方式
\begin{align} \operatorname { a} \left( \boldsymbol { h } _ { t } , \overline { \boldsymbol { h } } _ { s } \right) = \left\{ \begin{array} { l l } { \boldsymbol { h } _ { t } ^ { \top } \overline { \boldsymbol { h } } _ { s } } & { \text { dot } } \\ { \boldsymbol { h } _ { t } ^ { \top } \boldsymbol { W } _ { a } \overline { \boldsymbol { h } } _ { s } } & { \text { general } } \\ { \boldsymbol { W } _ { a } \left[ \boldsymbol { h } _ { t } ; \overline { \boldsymbol { h } } _ { s } \right] } & { \text { concat } } \end{array} \right. \end{align}
Highway
在"当我们在谈论 Deep Learning:CNN 其常见架构(下)"中我们介绍了 ResNet,它其实就是 Highway 演进出来的,不过当时并没有具体介绍,这里补充下。Highway Network 出自"Training Very Deep Networks",其表达式为
\mathbf { y } = H \left( \mathbf { x } , \mathbf { W } _ { \mathbf { H } } \right) \cdot T \left( \mathbf { x } , \mathbf { W } _ { \mathbf { T } } \right) + \mathbf { x } \cdot C \left( \mathbf { x } , \mathbf { W } _ { \mathbf { C } } \right)
类似 LSTM 中 gate 的概念,这里 T,H 分别被称为 transform gate、carry gate,分别表示输出多少是从变换来得,多少是从原始输入来的。为了减少参数,同时可以理解为归一化,文中令 C = 1 -T ,于是有
\mathbf { y } = H \left( \mathbf { x } , \mathbf { W } _ { \mathbf { H } } \right) \cdot T \left( \mathbf { x } , \mathbf { W } _ { \mathbf { T } } \right) + \mathbf { x } \cdot \left( 1 - T \left( \mathbf { x } , \mathbf { W } _ { \mathbf { T } } \right) \right)
其中, T ( \mathbf { x } ) = \sigma \left( \mathbf { W } _ { \mathbf { T } } ^ { T } \mathbf { x } + \mathbf { b } _ { \mathbf { T } } \right) , \sigma 为 sigmoid 函数, \sigma ( x ) \in ( 0,1 ) 。
Mel Spectrogram
做信号处理的同学都知道一般不会直接处理时域信号,而是会综合时频域分析,甚至频域分析更常用。语音信号处理同样,也会将时域信号变换到时频域提取特征,比如提取 Mel Spectrogram(梅尔频谱)。鉴于我只是语音的门外汉,大家可以参考"[STFT和声谱图,梅尔频谱(Mel Bank Features)",其中对 Mel Spectrogram 的概念及生成有较详细的介绍。
下面正式开始 Tacotron 的介绍。
Tacotron 简介
这里先简单介绍下 Tacotron 模型的输入输出:
- 输入、输出:如英语,输入即一句文本数据;输出是对应的语音信号的频谱,此文章中输出了两种频谱,Mel Spectrogram 与 Linear Spectrogram
- Loss Function:很符合直觉的,本文中 Loss 即 Mel Spectrogram Loss 、Linear Spectrogram Loss 的加权和
对于 Tacotron 模型的结构,主要由三个模块组成:Feature Extraction,Encoder-Decoder,Post-Process。其流程图如下
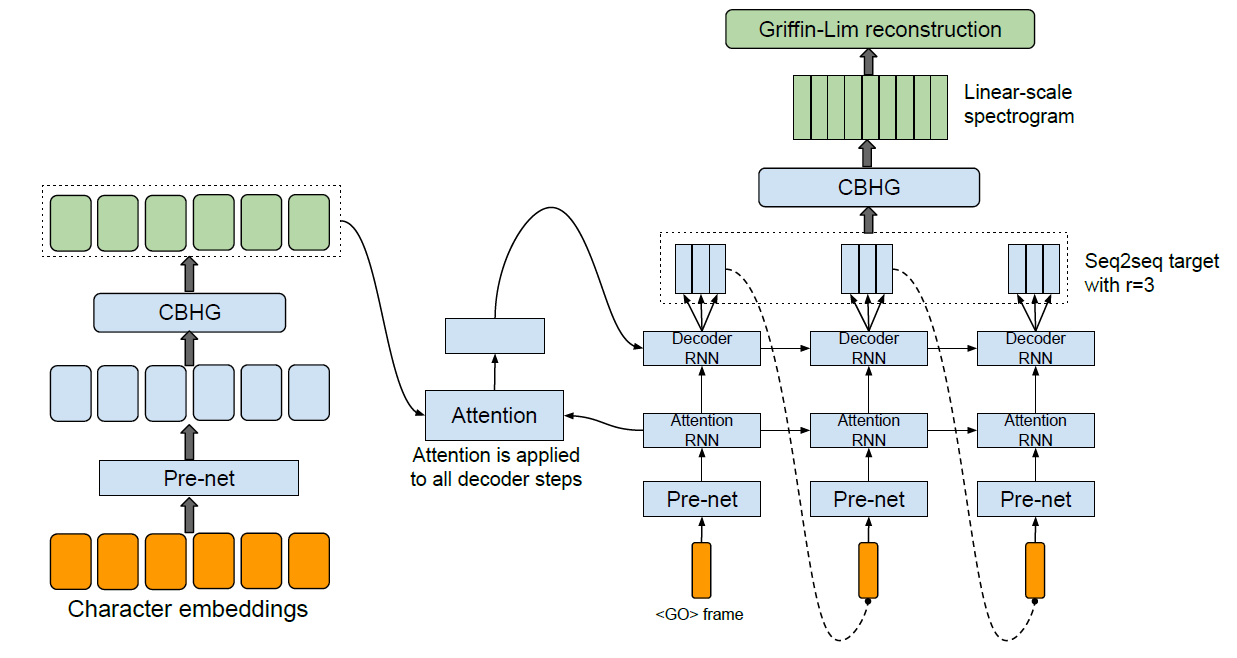
- Feature Extraction:如它名字所说,用于提取特征。首先对输入文本数据做 Character Embedding,然后通过 Pre-Net、CBHG 两个作者定义的网络,得到特征数据;
- Encoder-Decoder:本阶段是利用 Seq2Seq with Attention 网络,重构出频谱;
- Post-Process:这个阶段主要是优化重构出的频谱,并将频谱转换回时域。首先将 RNN 生成的 Mel Spectrogram 通过 CBHG 网络,生成 Linear Spectrogram(这样重复生成 Spectrogram 的原因我们下面再分析)。最后将 Linear Spectrogram 通过经典 Griffin-Lim 算法变换回时域得到语音信号。可以看到这里频域转时域的步骤已经跟网络没任何关系了,所以 Griffin-Lim 的细节下面不会讨论,有兴趣的同学可以自行查阅资料。
接下来,我们具体介绍这些模块。
Feature Extraction
这里主要包括 Character Embedding、 Pre-Net、CBHG 三个结构。为了方便后续理解,我们假设输入文本长度为 [charLen] 。
Character Embedding
Character Embedding 即字符级别的 Embedding,毕竟 word 的词库太大,而且意义也不大。此步骤输出大小为 [charLen, embedingSize]
Pre-Net
Pre-Net 也能一句话讲完,就是两层 Fully Connected 的网络罢了。但是需要注意的是,此时 Fully Connected 只针对 embedding 维,而非我们平时理解的"跟所有上一层元素都连接",所以此变换后输出为 [charLen, preNetUnitLen]
CBHG
这个阶段中比较复杂是作者定义的 CBHG 结构,它包含了一系列结构,示意图如下
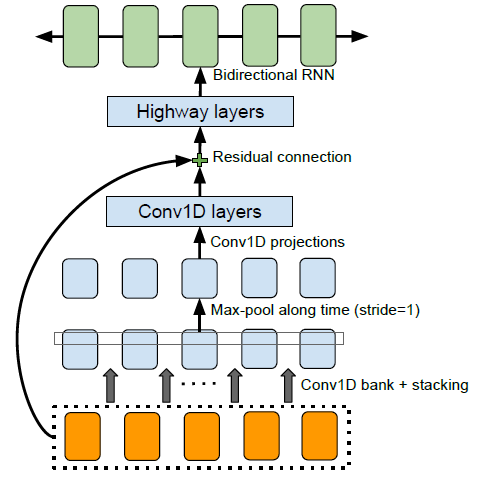
- Conv1D Bank: 这里 Bank 指的是 K 个一维卷积核,每个卷积核区别仅仅是大小不同,因此这里模拟的其实是抽取 1-Gram、2-Gram...、K-Gram 的特征,每个 filter 都能到 [charLen, cnnChannel] 大小的 Feature Map。然后将结果 stack 到一起,得到 [charLen * K, cnnChannel] 输出。
- Max-Pool along Time: 这跟普通 Pooling 也没什么区别,Pooling 的区域大小为 [poolSize, 1] ,在每个 Channel 上分别沿着时间的方向平移,于是输出依然是 [charLen * K, cnnChannel] 。这里作者强调了,他使用 stride=1,为的是保留时间上的分辨率
- Conv1D projections: 这是一层 Conv1D 的卷积
- Conv1D layers: 这依然是一层 Conv1D 的卷积
- Residual connections: 这是一层 Residual Block,即 H(x) = F(x) + x ,其具体解释与优点可以参考"当我们在谈论 Deep Learning:CNN 其常见架构(下)"
- Highway Layers: 接下来是一个多层的 Highway Layer,用于提取高维特征
最后,终于抽取了输入文本的特征。
Encoder-Decoder
Encoder
在 Encoder 阶段,作者将特征输入到一个 bidirectional GRU RNN 中。
Decoder
在 Decoder 阶段,利用 Attention RNN 得到 Mel Spectrogram。需要注意的是,在训练阶段,Attention RNN 的输入是 Ground Truth,仅在测试阶段是上一个 time step 的输出。其中 Attention RNN 输入需再次利用 Pre-Net 提取特征。
Attention 的结构上面已经介绍过,就不再赘述了。不过这里要吐槽一下 Google 的节操,在文中解释 Attention 引用的居然是自己公司的"Grammar as a Foreign Language,2015"而非更原始出处"Neural Machine Translation by Jointly Learning to Align and Translate, 2014",让人有种商业互吹、刷引用的既视感。
此外,此处 RNN 用的是多层的 GRU,与普通 GRU 稍微有些不同:这里 Layer 之间加入了 Residual Connections,按照文中的说法是能加速收敛,当然与此同时 Residual Block 的其他优点如稳定性更高、更易学习等是原因。关于 Residual Connections GRU 的具体介绍可以参考原文或"Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. 2016"。
Post-Process
这一步中,作者先用 CBHG 将 Decoder 产生的 Mel Spectrogram 转换为 Linear Spectrogram。文中提到增加这么一步的原因是,在 Decoder 中,产生的 frame 都是从前往后,而每个 frame 看到的信息也是从左往右的;而这一步中,每个 frame 能看到整句话的信息,可以帮助修正某些 frame 的错误。
最后,如上所述,就是利用 Griffin-Lim 算法得到时域语音信号,由于与整个网络结构无关,就不再赘述了。
上文提到,Tacotron 的 Loss Function 并非只是最终的 Linear Spectrogram 的 Loss,而是 Mel Spectrogram Loss、Linear Spectrogram Loss 的加权和。原因猜测跟 Mel Spectrogram 更符合人类的听觉特征有关,在 Loss 中加入 Mel Spectrogram 对产生的声谱是否符合人类听觉习惯增加了一定约束,提升听觉效果。
Tacotron 结构总结
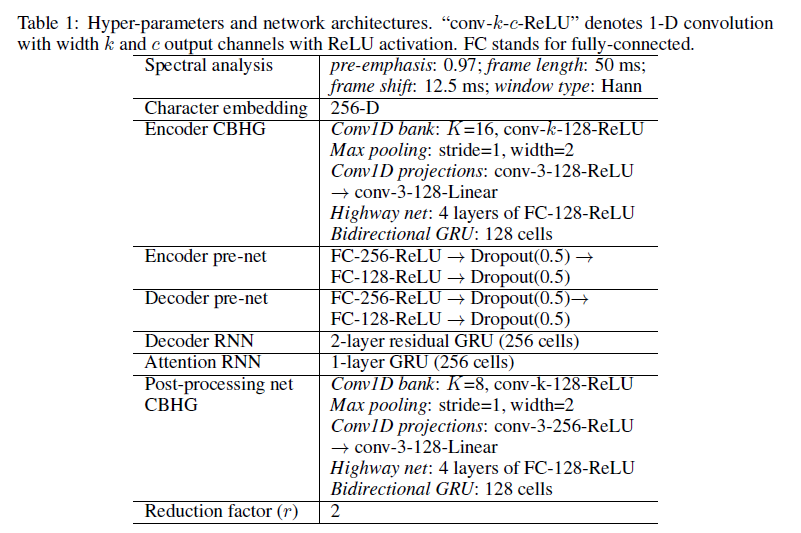
最后,下图列出 Tacotron 具体网络结构参数,有兴趣的可以对照着上文的介绍一起看看加深理解。
Tacotron 实验结果
为了一探如今 TTS 实际的效果,我最初毫无畏惧地用我的老爷 PC 跑起来 Tacotron 的训练代码。在运行了3天3夜才 20000 step,我听了听此时的效果,默默关掉了训练程序。。。不过我并没有死心,还强行尝试训练了日语,效果依然惨不忍睹。。。
后来我咨询了同事 (此处应@Max),才知道他们以前在微软都是用几十个GPU跑两天才出结果。怪不得网络上 TTS 的文章远少于 CV、NLP 的,看起来门槛高也是一个原因。
下面以英文为例,我给出 github 中有同学训练出的 Tacotron 效果,顺便也配上我自己的鬼畜音频,博大家一笑。日语的实在是太鬼畜,这里就不放了。下面每段视频的前半段是 Tacotron 正确的效果,后半段是我训练出来的鬼畜效果。
例句1:Scientists at the CERN laboratory say they have discovered a new particle.
例句2:There's a way to measure the acute emotional intelligence that has never gone out of style.
其他的例子就不再列举了,从上文两个示例也能看出,当前 Tacotron 的实际效果已然是非常惊艳,相信假以时日 TTS 真的能够做到以假乱真。
尾巴
这篇文章里提到了 Attention,这里顺便唠个八卦。记得去年曾经去听过一场 Chris Manning 的报告,他提到他们团队的工作现在也都基本标配 Attention,我当时还问了一句,大概是:在你们的实验中,Attention 的效果总是优于没有 Attention 吗?Chris Manning 回答:YES,ALWAYS。所以感觉有条件的,可以无脑上 Attention 了,当然学术界早已如此。
另外,恰好最近"命运石之门0"完结,倒数第二集真是把 Amadesu 的美丽和声音表现的太棒了!而回到现实,Amadesu 这种真-AI 短期不一定能实现,但是其中令她说话如真人一般自然且有感情的 TTS 模块的到来,相信不会太遥远了。
REFERENCE
- tacotron 开源代码
本系列其他文章:
专栏总目录(新)

没有评论:
发表评论