
栗子 假装发自 东京 量子位 报道 | 公众号 QbitAI

快到飞起。
昨天,东京,"教主"黄仁勋发布了一枚新GPU:Tesla T4。
按照英伟达的说法,Tesla T4是为推理而生的。
2,560个CUDA,320个张量核心 (Tensor Core) ,推理加速表现如下。
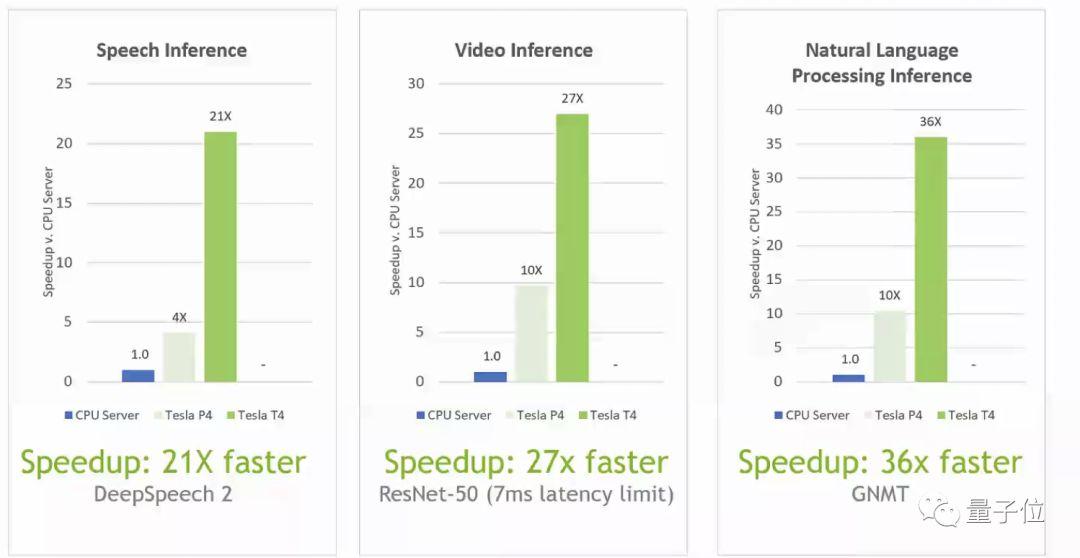
比赛结束,基于帕斯卡架构的P4前辈,在T4面前输得很惨:
在语音识别模型DeepSpeech 2上,T4比P4的5倍还要快;在神经网络翻译模型GNMT上,T4的速度接近P4的4倍;在图像识别模型ResNet-50上,T4也接近P4的3倍。
注意,在T4诞生之前,P4在深度学习界的地位,也是很崇高的。
Tesla T4快在哪里
算力的增长,图灵架构里的张量核心 (Tensor Core) 是重中之重。
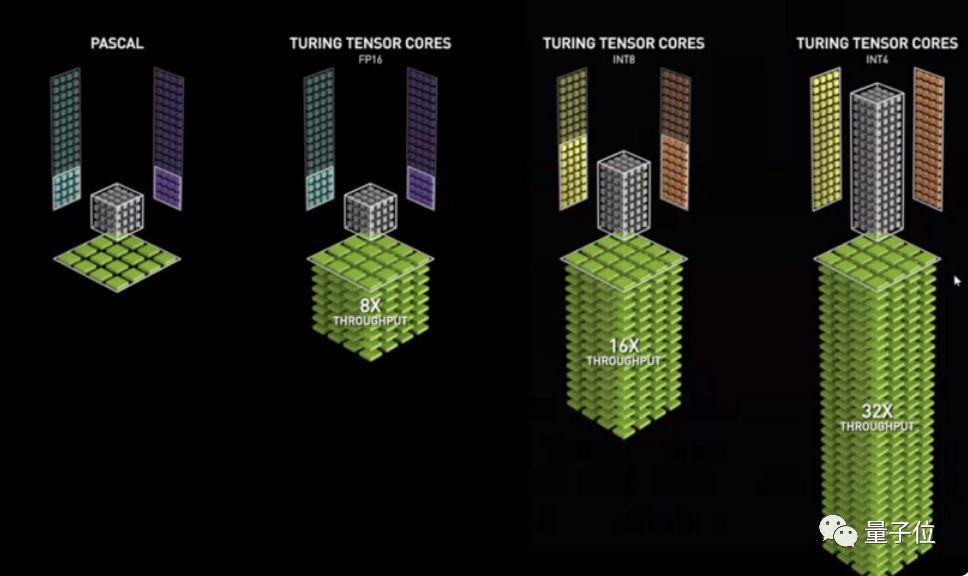
T4的320个张量核心,让数据吞吐量疾速增长,峰值达到260 TOPS (精度INT4) 。
再回头看两年前的P4:
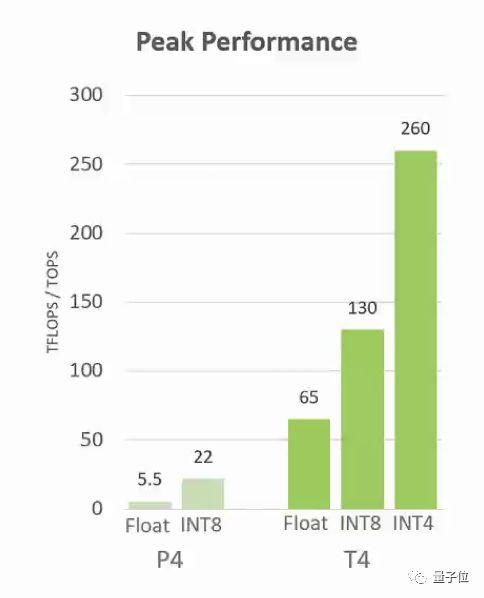
别看速度提升那么多,Tesla T4的功耗 (TDP) 依然停留在谦虚的75瓦。
这样的GPU,哪里需要哪里搬,英伟达称之为"宇宙通用推理加速器 (Universal Inference Accelerator) " 。
把参数排列起来,是不是更燃:

顺便,T4的显存为16GB GDDR6,带宽为320+GB/s。

以RTX为名的显卡,不论是专业级的Quadro系列还是游戏显卡Geforce系列,都是在T4的关怀之下,学习光线追踪技巧的。哪里该有光亮,哪里该是阴影,几乎不会错。
TensorRT也更新了
TensorRT 5
加速推理,是一项宏伟的事业,只有GPU是不够的。
和Tesla T4一同发布的,是TensorRT 5推理加速引擎。
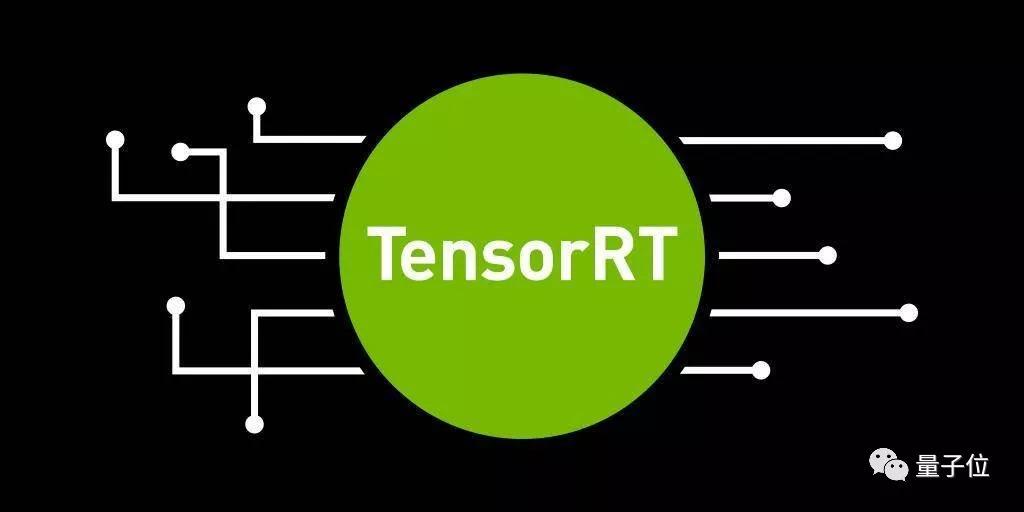
这一次更新,主要是为图灵架构提供支持,最高可以达到CPU 40倍的推理速度。
5.0版本中,有8个新的API (精度INT8) ,用于优化推理模型,神经网络翻译也好,推荐系统也好。
现在,TensorRT已经可以和TensorFlow集成,和MatLab集成,ONNX也没放过。

TensorRT推理服务器
除此之外,搭配着引擎食用的TensorRT推理服务器,也一起发布了,做足全套功课。
服务器的作用,是提升GPU的利用率,在一个节点上同时运行不同框架上的多个模型。以下是一个"学跳舞"模型的生成效果举栗。

原来是这样啊:

现在,推理服务器的测试版本已经提供下载了,大家可以试试看:
https://ift.tt/2OgV9Z3
进击的AGX
有些推理,可以永远留在计算机里。
还有一些,就需要接受现实世界的调教了。

针对机器人的大脑,以及其他自动化设备的大脑,英伟达也发布了一系列AGX系统:
Jetson AGX,Drive AGX以及Clara AGX皆在此列,是基于Xavier芯片打造的开发包 (Devkit) 。
先说Drive AGX,顾名思义,用来开发自动驾驶应用。开发包里有一台计算机,搭载了Drive软件,可以与汽车联动。

这台电脑,只是老黄在发布会上举起的许多重物之中,比较轻的一个。
团队希望,开发者能在这"大脑"里,写出各式各样的脑回路,帮助自动驾驶汽车适应艰险的路况。
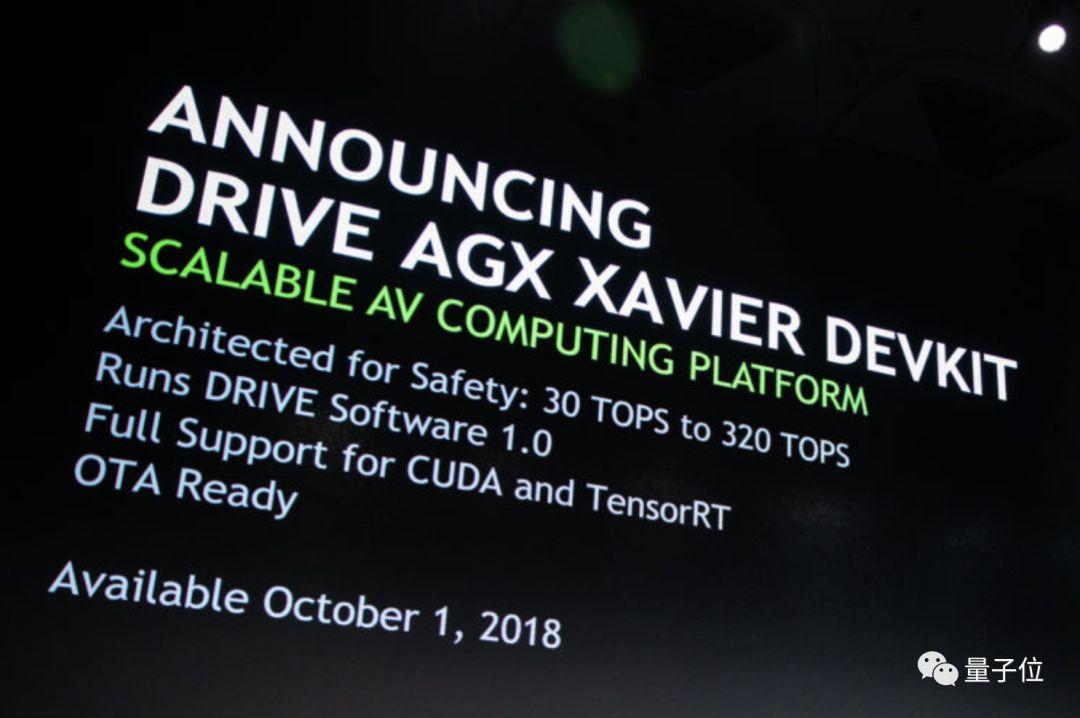
Drive AGX开发包,10月1日开始发售。
Jetson AGX与之同理,只是用于工业场景。在人口老龄化形势严峻的日本,工业自动化尤其受到重视。
英伟达说,Jetson AGX是全球第一台为自动化设备定制的计算机。工程机械巨头小松制作所等许多企业已经投入使用了。
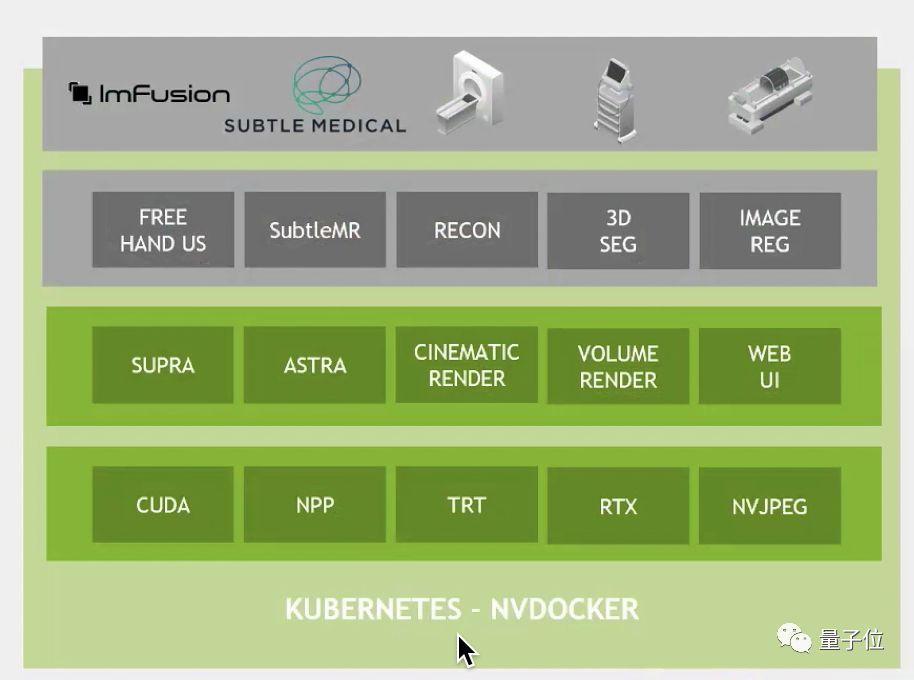
Clara AGX是医疗场景下的开发包,但这里没有计算机,只是纯纯的SDK:
一句重要的话
如果想要申请谷歌云上的T4早期试用,请在这里填表:
https://ift.tt/2xcuZR3
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI· 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态

没有评论:
发表评论