
伊瓢 发自 凹非寺 量子位 报道 | 公众号 QbitAI
在高帧数下,如何实现人体姿态检测?
下面这条刷屏的twitter视频给出了答案。
这是今年ECCV上的一篇名为《Pose Proposal Networks》的论文,作者是日本柯尼卡美能达公司的関井大気(Taiki SEKII),结合了去年CVPR上的YOLO和CMU的OpenPose,创造出的新方法,能够实现高帧数视频中的多人姿态检测。
高帧数,无压力
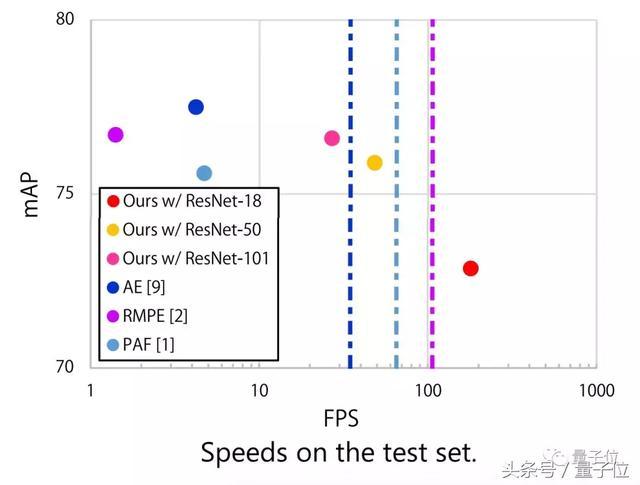
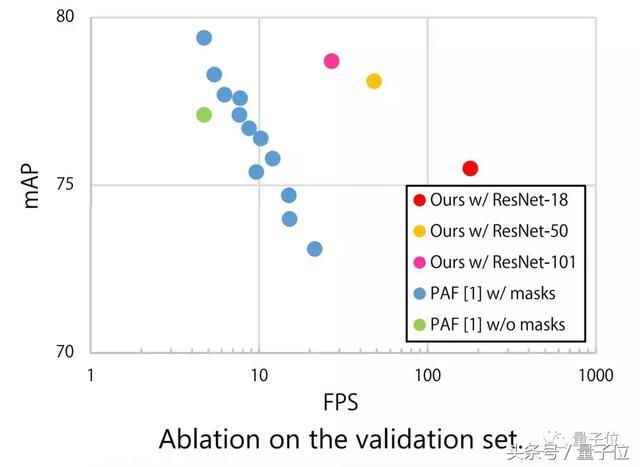
而其他方法,比如NIPS 2017 的AE(Associative embedding)、ICCV 2017的RMPE(Regional multi-person pose estimation)、CVPR 2017的PAF(Realtime multi-person 2D pose estimation using part affinity fields),都无法实现高帧数尤其是100以上帧数视频的姿态检测。
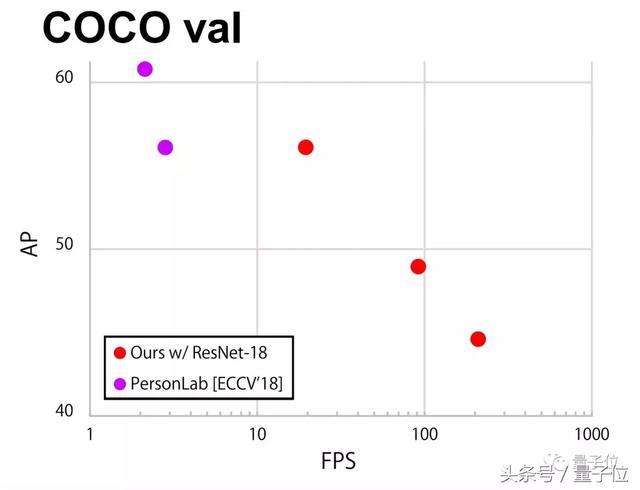
在COCO数据集上也不虚,相比谷歌PersonLab能在更高帧数下运行。
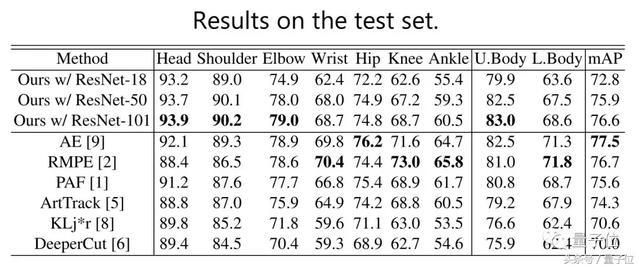
来看下具体数据,在头、肩、肘部位和整体上半身识别中超过了其他方法,整体得分也不虚。
神奇"体位"大冒险
另外,常规的姿态检测十分容易出错的"体位"中,该方法也可以规避。
比如从天上跳伞下来这种奇怪的姿势:

人数过多的拥挤场景:

还有,两个人重叠的图像。
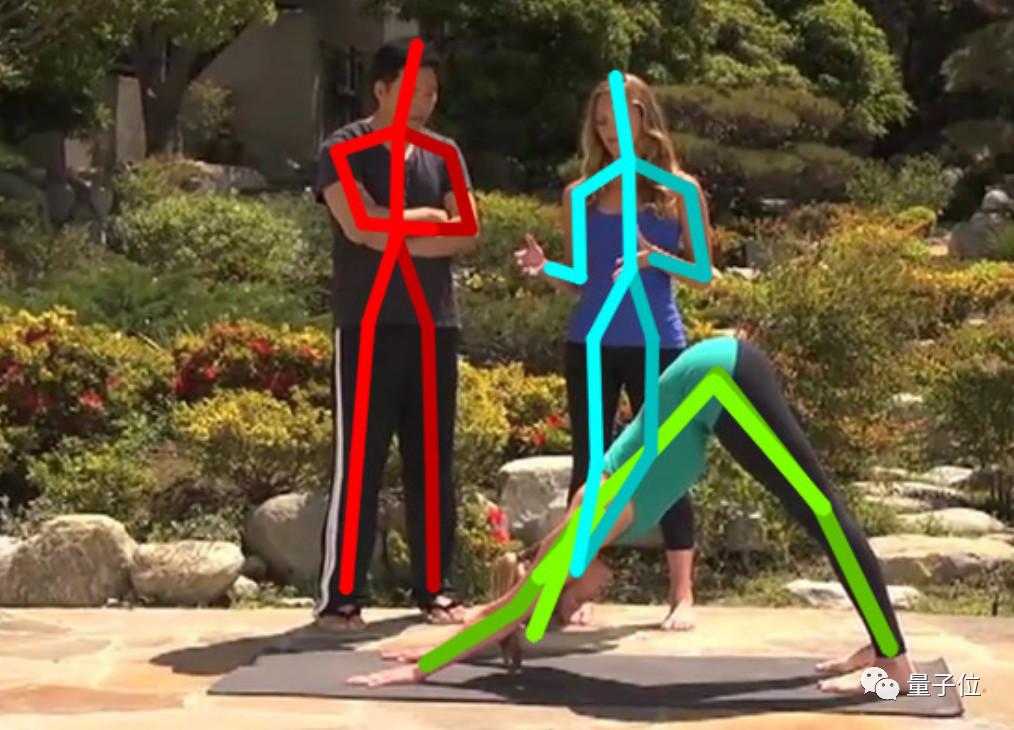
注意,右侧站立的女子和她前面在瑜伽垫上的人,完完全全分开了,不会闹出下面这种胳膊腿儿搞错的笑话。

原理

这是基于ResNet-18的PPN对多人姿势检测的过程:
a) 输入图像;
b) 从输入图像中检测部分边界框;
c) 检测出肢体;
d) 区分图中每个人。
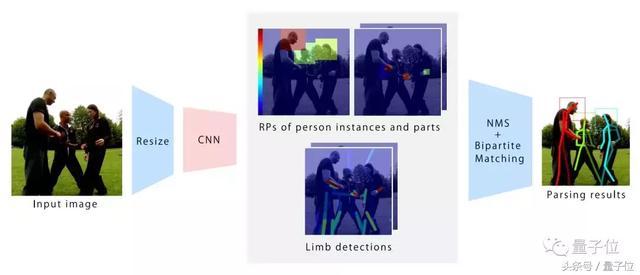
这篇论文的方法是先将图片分割为较小的网格,使用较小的网络对每一幅网格图片进行单次物体检测范例,之后通过区域提议(region proposal)框架将姿态检测重定义为目标检测问题。
之后,使用单次CNN直接检测肢体,通过新颖的概率贪婪解析步骤,生成姿势提议。
区域提案部分被定义为边界框检测(Bounding Box Detections),大小和被检测人身材成比例,并且可以仅使用公共关键点注释进行监督。
整个架构由单个完全CNN构成,具有相对较低分辨率的特征图,并使用专为姿势检测性能设计的损耗函数直接进行端到端优化,此架构称为姿态提议网络(Pose Proposal Network,PPN)。PPN借鉴了YOLO的优点。
传送门
论文:
https://ift.tt/2MbDWP8
Poster:
https://ift.tt/2Mc5V17
至于code嘛,暂时没有。
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI· 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态

没有评论:
发表评论