
车栗子 发自 凹非寺量子位 出品 | 公众号 QbitAI

自动驾驶汽车,需要应对各式各样的路况,工作环境是每时每刻在变化的。
所以,训练好L4级的自动驾驶系统并不简单。需要依赖奖励函数 (Reward Function) 和代价函数 (Cost Function) 。
如此一来,研究人员需要花大量精力,给强化学习里的这些函数调参。环境越复杂,调参的工作就越难做。

不过,百度自动驾驶部门的人类,想要解放双手,将调参重任托付给AI自己。
于是,他们开发了自动调参方法,让AI能够用更短的训练时间,获得应对复杂驾驶场景的能力。
划重点:快速适应多种环境。
离线调参更安全
自动驾驶汽车,需要能应付各种场景的AI系统。

这个动作规划系统,是基于百度Apollo自动驾驶框架研发的。
系统是数据驱动的,用到的数据包括专家驾驶数据和周围环境数据。
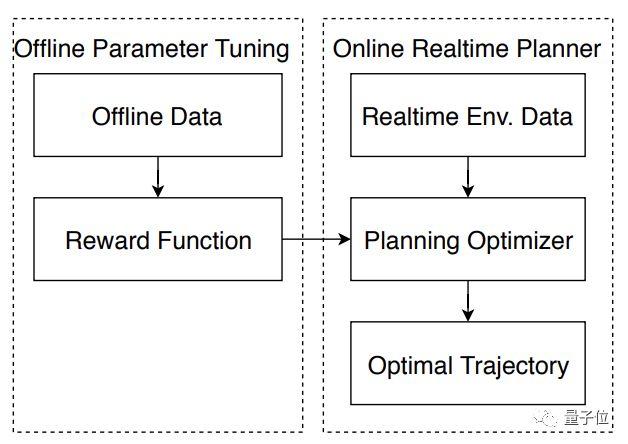
上图可以看出,系统分为离线和在线两个部分:
1.在线模块,负责生成一条最优的运动轨迹,用的是奖励函数。2.离线调参模块,才是用来生成奖励函数和代价函数的,且是可以随着环境调整的函数。
所以,第二部分是重点。要看一组参数好不好,模拟测试和路测都不可少 (如下图) 。
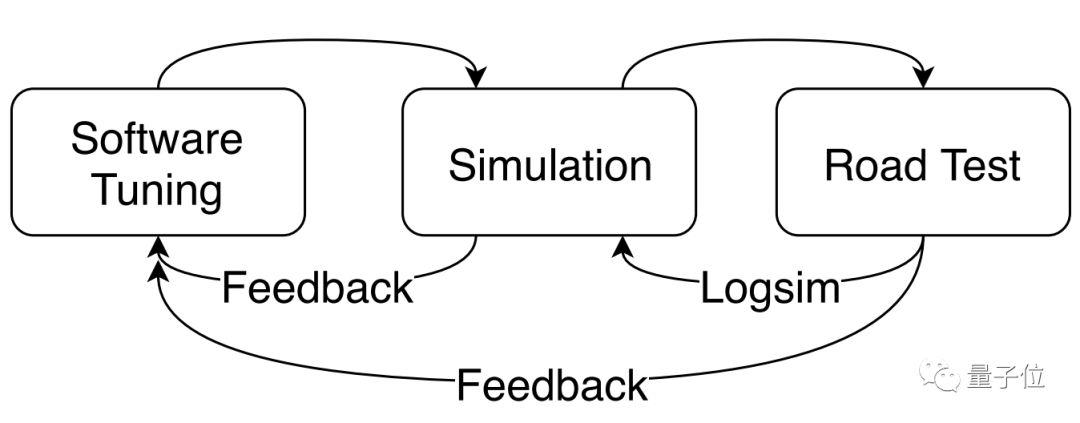
为了减少反馈循环 (Feedback Cycles) 消耗的时间,百度用基于排名的条件逆强化学习 (Rank Based Conditional IRL) 框架,来调教奖励/代价函数,代替漫长的手动调参。
模型是如何炼成的
那么,看看模型具体的样子:
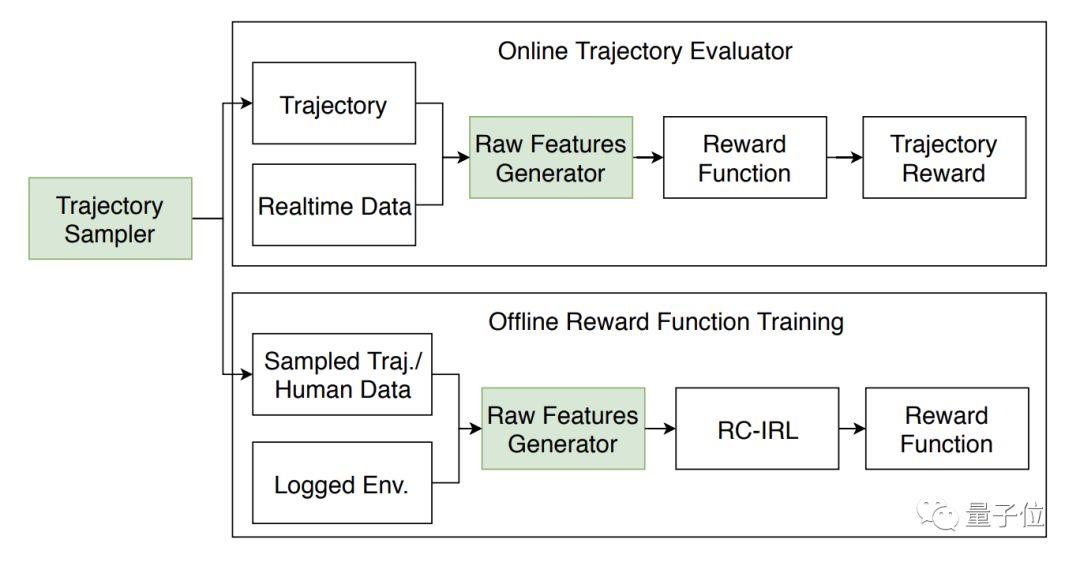
还是在线和离线两部分,不过可以看出这个新的强化学习调参框架 (RC-IRL) 所在的位置了。
工作流程
原始特征生成器 (Raw Feature Generator),从环境里获取输入,评估采样轨迹或者专家驾驶轨迹。从中选出一些轨迹,给在线模块和离线模块共同使用。
从轨迹中,把原始特征提取出来之后,在线评估器中的奖励/代价函数,会给出一个分数。
最后,把分数排列出来,或者用动态规划 (Dynamic Programming) ,来选择最终输出的一条轨迹。
训练过程
训练数据是从1000+小时的专家驾驶数据里选出来的,把没有障碍物又没有车速变化的部分剔除了,余下7.18亿帧,保障训练的难度。
训练过程是离线的,适用于大规模测试,也适用于处理边角案例 (Corner Cases) 。
另外,数据也是自动收集、自动标注的,又为人类节省了体力。
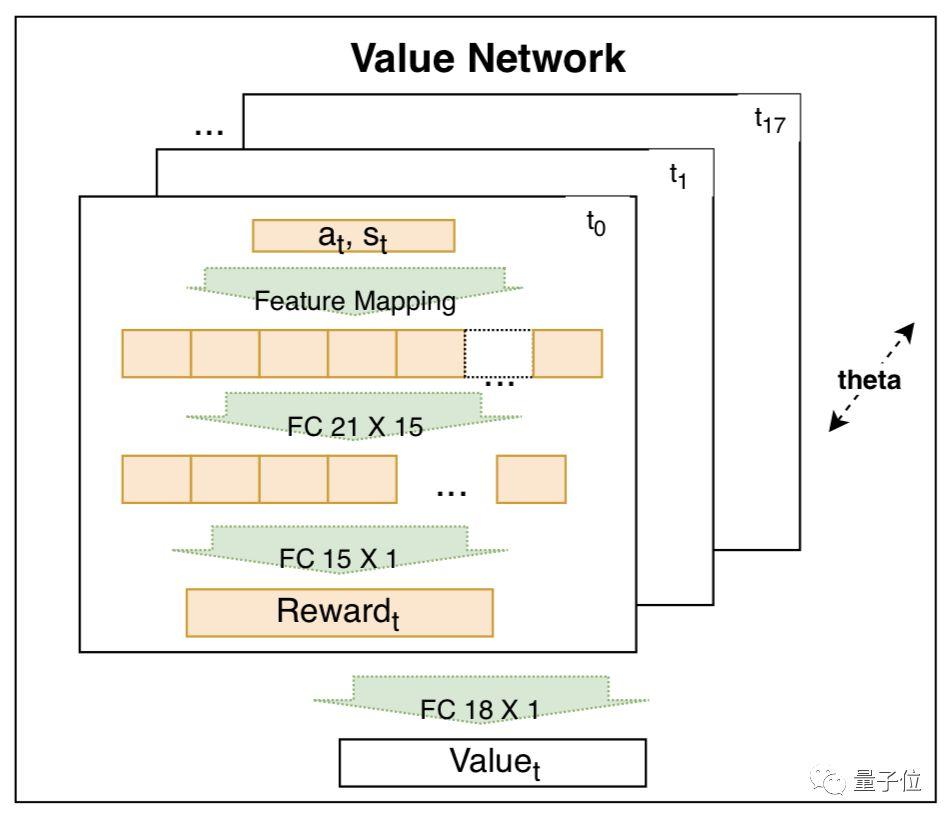
价值函数,用SIAMESE网络来训练。这一部分,是用来捕捉驾驶行为的,依据许多特征来捕捉。
训练好了,就去参加测试。模拟测试的内容包括:停车,转弯,变线,超车以及更加复杂的场景。
模拟器之后是路测。截至今年7月25日,系统已经历了超过25,000英里的路测。团队说,AI到目前为止表现良好。
再赢一次?
两天前,百度宣布和神州优车达成合作,一同探索自动驾驶技术的商业化。
一周前,Waymo子公司"惠摩"落户上海。
自动驾驶的赛场上,谁也不会放慢脚步。
有一天,如果Waymo无人车来了中国,不知百度能不能"再赢一次"。
论文传送门:
https://arxiv.org/pdf/1808.04913.pdf
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI· 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态

没有评论:
发表评论