
方栗子 编译自 GitHub量子位 出品 | 公众号 QbitAI

妈妈小时候已经有彩色照片了,不过那些照片,还是照相馆的人类手动上色的。
几十年之后,人们已经开始培育深度神经网络,来给老照片和老电影上色了。
来自哈佛大学的Luke Melas-Kyriazi (我叫他卢克吧) ,用自己训练的神经网络,把电影里的卓别林变成了彩色的卓别林,清新自然。
作为一只哈佛学霸,卢克还为钻研机器学习的小伙伴们写了一个基于PyTorch的教程。
虽然教程里的模型比给卓别林用的模型要简约一些,但效果也是不错了。
问题是什么?
卢克说,给黑白照片上色这个问题的难点在于,它是多模态的——与一幅灰度图像对应的合理彩色图像,并不唯一。

传统模型需要输入许多额外信息,来辅助上色。
而深度神经网络,除了灰度图像之外,不需要任何额外输入,就可以完成上色。
在彩色图像里,每个像素包含三个值,即亮度、饱和度以及色调。
而灰度图像,并无饱和度和色调可言,只有亮度一个值。

所以,模型要用一组数据,生成另外两足数据。换句话说,以灰度图像为起点,推断出对应的彩色图像。
为了简单,这里只做了256 x 256像素的图像上色。输出的数据量则是256 x 256 x 2。
关于颜色表示,卢克用的是LAB色彩空间,它跟RGB系统包含的信息是一样的。
但对程序猿来说,前者比较方便把亮度和其他两项分离开来。

数据也不难获得,卢克用了MIT Places数据集,中的一部分。内容就是校园里的一些地标和风景。然后转换成黑白图像,就可以了。以下为数据搬运代码——
1 # Download and unzip (2.2GB) 2 !wget http://data.csail.mit.edu/places/places205/testSetPlaces205_resize.tar.gz 3 !tar -xzf testSetPlaces205_resize.tar.gz 1 # Move data into training and validation directories 2 import os 3 os.makedirs('images/train/class/', exist_ok=True) # 40,000 images 4 os.makedirs('images/val/class/', exist_ok=True) # 1,000 images 5 for i, file in enumerate(os.listdir('testSet_resize')): 6 if i < 1000: # first 1000 will be val 7 os.rename('testSet_resize/' + file, 'images/val/class/' + file) 8 else: # others will be val 9 os.rename('testSet_resize/' + file, 'images/train/class/' + file) 1 # Make sure the images are there 2 from IPython.display import Image, display 3 display(Image(filename='images/val/class/84b3ccd8209a4db1835988d28adfed4c.jpg'))
好用的工具有哪些?
搭建模型和训练模型是在PyTorch里完成的。
还用了torchvishion,这是一套在PyTorch上处理图像和视频的工具。
另外,scikit-learn能完成图片在RGB和LAB色彩空间之间的转换。
1 # Download and import libraries 2 !pip install torch torchvision matplotlib numpy scikit-image pillow==4.1.1 1 # For plotting 2 import numpy as np 3 import matplotlib.pyplot as plt 4 %matplotlib inline 5 # For conversion 6 from skimage.color import lab2rgb, rgb2lab, rgb2gray 7 from skimage import io 8 # For everything 9 import torch 10 import torch.nn as nn 11 import torch.nn.functional as F 12 # For our model 13 import torchvision.models as models 14 from torchvision import datasets, transforms 15 # For utilities 16 import os, shutil, time 1 # Check if GPU is available 2 use_gpu = torch.cuda.is_available()
模型长什么样?
神经网络里面,第一部分是几层用来提取图像特征;第二部分是一些反卷积层 (Deconvolutional Layers) ,用来给那些特征增加分辨率。
具体来说,第一部分用的是ResNet-18,这是一个图像分类网络,有18层,以及一些残差连接 (Residual Connections) 。
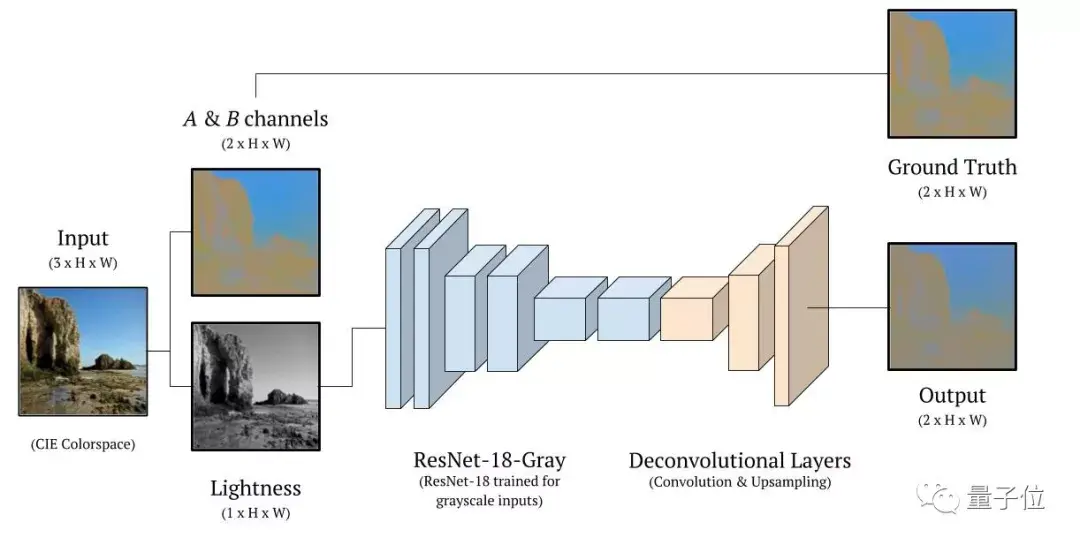
给第一层做些修改,它就可以接受灰度图像输入了。然后把第6层之后的都去掉。
然后,用代码来定义一下这个模型。
从神经网络的第二部分 (就是那些上采样层) 开始。
1 class ColorizationNet(nn.Module): 2 def __init__(self, input_size=128): 3 super(ColorizationNet, self).__init__() 4 MIDLEVEL_FEATURE_SIZE = 128 5 6 ## First half: ResNet 7 resnet = models.resnet18(num_classes=365) 8 # Change first conv layer to accept single-channel (grayscale) input 9 resnet.conv1.weight = nn.Parameter(resnet.conv1.weight.sum(dim=1).unsqueeze(1)) 10 # Extract midlevel features from ResNet-gray 11 self.midlevel_resnet = nn.Sequential(*list(resnet.children())[0:6]) 12 13 ## Second half: Upsampling 14 self.upsample = nn.Sequential( 15 nn.Conv2d(MIDLEVEL_FEATURE_SIZE, 128, kernel_size=3, stride=1, padding=1), 16 nn.BatchNorm2d(128), 17 nn.ReLU(), 18 nn.Upsample(scale_factor=2), 19 nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1), 20 nn.BatchNorm2d(64), 21 nn.ReLU(), 22 nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1), 23 nn.BatchNorm2d(64), 24 nn.ReLU(), 25 nn.Upsample(scale_factor=2), 26 nn.Conv2d(64, 32, kernel_size=3, stride=1, padding=1), 27 nn.BatchNorm2d(32), 28 nn.ReLU(), 29 nn.Conv2d(32, 2, kernel_size=3, stride=1, padding=1), 30 nn.Upsample(scale_factor=2) 31 ) 32 33 def forward(self, input): 34 35 # Pass input through ResNet-gray to extract features 36 midlevel_features = self.midlevel_resnet(input) 37 38 # Upsample to get colors 39 output = self.upsample(midlevel_features) 40 return output
下一步,创建模型吧。
1 model = ColorizationNet()
它是怎么训练的?
预测每个像素的色值,用的是回归 (Regression) 的方法。
损失函数 (Loss Function)
所以,用了一个均方误差 (MSE) 损失函数——让预测的色值与参考标准 (Ground Truth) 之间的距离平方最小化。
1 criterion = nn.MSELoss()
优化损失函数
这里是用Adam Optimizer优化的。
1 optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, weight_decay=0.0)
加载数据
用torchtext加载数据。首先定义一个专属的数据加载器 (DataLoader) ,来完成RGB到LAB空间的转换。
1 class GrayscaleImageFolder(datasets.ImageFolder): 2 '''Custom images folder, which converts images to grayscale before loading''' 3 def __getitem__(self, index): 4 path, target = self.imgs[index] 5 img = self.loader(path) 6 if self.transform is not None: 7 img_original = self.transform(img) 8 img_original = np.asarray(img_original) 9 img_lab = rgb2lab(img_original) 10 img_lab = (img_lab + 128) / 255 11 img_ab = img_lab[:, :, 1:3] 12 img_ab = torch.from_numpy(img_ab.transpose((2, 0, 1))).float() 13 img_original = rgb2gray(img_original) 14 img_original = torch.from_numpy(img_original).unsqueeze(0).float() 15 if self.target_transform is not None: 16 target = self.target_transform(target) 17 return img_original, img_ab, target
再来,就是定义训练数据和验证数据的转换。
1 # Training 2 train_transforms = transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip()]) 3 train_imagefolder = GrayscaleImageFolder('images/train', train_transforms) 4 train_loader = torch.utils.data.DataLoader(train_imagefolder, batch_size=64, shuffle=True) 5 6 # Validation 7 val_transforms = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224)]) 8 val_imagefolder = GrayscaleImageFolder('images/val' , val_transforms) 9 val_loader = torch.utils.data.DataLoader(val_imagefolder, batch_size=64, shuffle=False)
辅助函数 (Helper Function)
训练开始之前,要把辅助函数写好,来追踪训练损失,并把图像转回RGB形式。
1 class AverageMeter(object): 2 '''A handy class from the PyTorch ImageNet tutorial''' 3 def __init__(self): 4 self.reset() 5 def reset(self): 6 self.val, self.avg, self.sum, self.count = 0, 0, 0, 0 7 def update(self, val, n=1): 8 self.val = val 9 self.sum += val * n 10 self.count += n 11 self.avg = self.sum / self.count 12 13 def to_rgb(grayscale_input, ab_input, save_path=None, save_name=None): 14 '''Show/save rgb image from grayscale and ab channels 15 Input save_path in the form {'grayscale': '/path/', 'colorized': '/path/'}''' 16 plt.clf() # clear matplotlib 17 color_image = torch.cat((grayscale_input, ab_input), 0).numpy() # combine channels 18 color_image = color_image.transpose((1, 2, 0)) # rescale for matplotlib 19 color_image[:, :, 0:1] = color_image[:, :, 0:1] * 100 20 color_image[:, :, 1:3] = color_image[:, :, 1:3] * 255 - 128 21 color_image = lab2rgb(color_image.astype(np.float64)) 22 grayscale_input = grayscale_input.squeeze().numpy() 23 if save_path is not None and save_name is not None: 24 plt.imsave(arr=grayscale_input, fname='{}{}'.format(save_path['grayscale'], save_name), cmap='gray') 25 plt.imsave(arr=color_image, fname='{}{}'.format(save_path['colorized'], save_name))
验证
不用反向传播 (Back Propagation),直接用torch.no_grad() 跑模型。
1 def validate(val_loader, model, criterion, save_images, epoch): 2 model.eval() 3 4 # Prepare value counters and timers 5 batch_time, data_time, losses = AverageMeter(), AverageMeter(), AverageMeter() 6 7 end = time.time() 8 already_saved_images = False 9 for i, (input_gray, input_ab, target) in enumerate(val_loader): 10 data_time.update(time.time() - end) 11 12 # Use GPU 13 if use_gpu: input_gray, input_ab, target = input_gray.cuda(), input_ab.cuda(), target.cuda() 14 15 # Run model and record loss 16 output_ab = model(input_gray) # throw away class predictions 17 loss = criterion(output_ab, input_ab) 18 losses.update(loss.item(), input_gray.size(0)) 19 20 # Save images to file 21 if save_images and not already_saved_images: 22 already_saved_images = True 23 for j in range(min(len(output_ab), 10)): # save at most 5 images 24 save_path = {'grayscale': 'outputs/gray/', 'colorized': 'outputs/color/'} 25 save_name = 'img-{}-epoch-{}.jpg'.format(i * val_loader.batch_size + j, epoch) 26 to_rgb(input_gray[j].cpu(), ab_input=output_ab[j].detach().cpu(), save_path=save_path, save_name=save_name) 27 28 # Record time to do forward passes and save images 29 batch_time.update(time.time() - end) 30 end = time.time() 31 32 # Print model accuracy -- in the code below, val refers to both value and validation 33 if i % 25 == 0: 34 print('Validate: [{0}/{1}]\t' 35 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' 36 'Loss {loss.val:.4f} ({loss.avg:.4f})\t'.format( 37 i, len(val_loader), batch_time=batch_time, loss=losses)) 38 39 print('Finished validation.') 40 return losses.avg
训练用loss.backward(),用上反向传播。写一下训练数据跑一遍 (one epoch) 用的函数。
1 def train(train_loader, model, criterion, optimizer, epoch): 2 print('Starting training epoch {}'.format(epoch)) 3 model.train() 4 5 # Prepare value counters and timers 6 batch_time, data_time, losses = AverageMeter(), AverageMeter(), AverageMeter() 7 8 end = time.time() 9 for i, (input_gray, input_ab, target) in enumerate(train_loader): 10 11 # Use GPU if available 12 if use_gpu: input_gray, input_ab, target = input_gray.cuda(), input_ab.cuda(), target.cuda() 13 14 # Record time to load data (above) 15 data_time.update(time.time() - end) 16 17 # Run forward pass 18 output_ab = model(input_gray) 19 loss = criterion(output_ab, input_ab) 20 losses.update(loss.item(), input_gray.size(0)) 21 22 # Compute gradient and optimize 23 optimizer.zero_grad() 24 loss.backward() 25 optimizer.step() 26 27 # Record time to do forward and backward passes 28 batch_time.update(time.time() - end) 29 end = time.time() 30 31 # Print model accuracy -- in the code below, val refers to value, not validation 32 if i % 25 == 0: 33 print('Epoch: [{0}][{1}/{2}]\t' 34 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' 35 'Data {data_time.val:.3f} ({data_time.avg:.3f})\t' 36 'Loss {loss.val:.4f} ({loss.avg:.4f})\t'.format( 37 epoch, i, len(train_loader), batch_time=batch_time, 38 data_time=data_time, loss=losses)) 39 40 print('Finished training epoch {}'.format(epoch))
然后,定义一个训练回路 (Training Loop) ,跑一百遍训练数据。从Epoch 0开始训练。
1 # Move model and loss function to GPU 2 if use_gpu: 3 criterion = criterion.cuda() 4 model = model.cuda() 1 # Make folders and set parameters 2 os.makedirs('outputs/color', exist_ok=True) 3 os.makedirs('outputs/gray', exist_ok=True) 4 os.makedirs('checkpoints', exist_ok=True) 5 save_images = True 6 best_losses = 1e10 7 epochs = 100 1 # Train model 2 for epoch in range(epochs): 3 # Train for one epoch, then validate 4 train(train_loader, model, criterion, optimizer, epoch) 5 with torch.no_grad(): 6 losses = validate(val_loader, model, criterion, save_images, epoch) 7 # Save checkpoint and replace old best model if current model is better 8 if losses < best_losses: 9 best_losses = losses 10 torch.save(model.state_dict(), 'checkpoints/model-epoch-{}-losses-{:.3f}.pth'.format(epoch+1,losses))
训练结果什么样?
是时候看看修炼成果了,所以,复制一下这段代码。
1 # Show images 2 import matplotlib.image as mpimg 3 image_pairs = [('outputs/color/img-2-epoch-0.jpg', 'outputs/gray/img-2-epoch-0.jpg'), 4 ('outputs/color/img-7-epoch-0.jpg', 'outputs/gray/img-7-epoch-0.jpg')] 5 for c, g in image_pairs: 6 color = mpimg.imread(c) 7 gray = mpimg.imread(g) 8 f, axarr = plt.subplots(1, 2) 9 f.set_size_inches(15, 15) 10 axarr[0].imshow(gray, cmap='gray') 11 axarr[1].imshow(color) 12 axarr[0].axis('off'), axarr[1].axis('off') 13 plt.show()
效果还是很自然的,虽然生成的彩色图像不是那么明丽。


卢克说,问题是多模态的,所以损失函数还是值得推敲。
比如,一条灰色裙子可以是蓝色也可以是红色。如果模型选择的颜色和参考标准不同,就会受到严厉的惩罚。
这样一来,模型就会选择哪些不会被判为大错特错的颜色,而不太选择非常显眼明亮的颜色。
没时间怎么办?
卢克还把一只训练好的AI放了出来,不想从零开始训练的小伙伴们,也可以直接感受他的训练成果,只要用以下代码下载就好了。
1 # Download pretrained model 2 !wget https://www.dropbox.com/s/kz76e7gv2ivmu8p/model-epoch-93.pth 3 #https://www.dropbox.com/s/9j9rvaw2fo1osyj/model-epoch-67.pth 1 # Load model 2 pretrained = torch.load('model-epoch-93.pth', map_location=lambda storage, loc: storage) 3 model.load_state_dict(pretrained) 1# Validate 2 save_images = True 3 with torch.no_grad(): 4 validate(val_loader, model, criterion, save_images, 0)
彩色老电影?
如果想要更加有声有色的结局,就不能继续偷懒了。卢克希望大家沿着他精心铺就的路,走到更远的地方。

要替换当前的损失函数,可以参考Zhang et al. (2017):https://ift.tt/2q5En3V
无监督学习的上色大法,可以参考Larsson et al. (2017):https://ift.tt/2IW1WZF
另外,可以做个手机应用,就像谷歌在I/O大会上发布的着色软件那样。
黑白电影,也可以自己去尝试,一帧一帧地上色。
这里有卓别林用到的完整代码:
https://ift.tt/2xo8gE5

— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态

没有评论:
发表评论