
夏乙 发自 凹非寺量子位 出品 | 公众号 QbitAI
来,看一段亦可赛艇的视频。

一只其貌不扬的机械臂,颤巍巍地逐渐靠近塑料圆环,弯曲、抬起、带走它、移到旁边的圆柱上、伸直、放下它……
这有什么稀奇?
秘密就在机械臂上方两侧粉嫩嫩的部分。
那是,活生生的,肌肉!
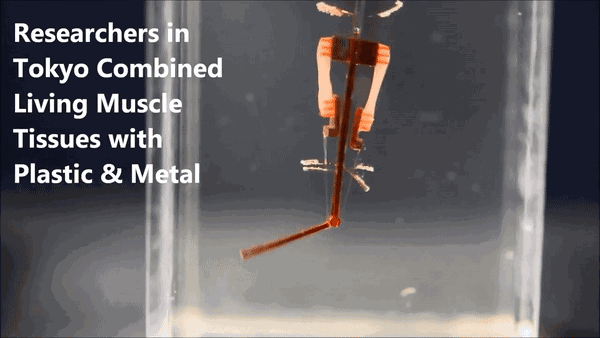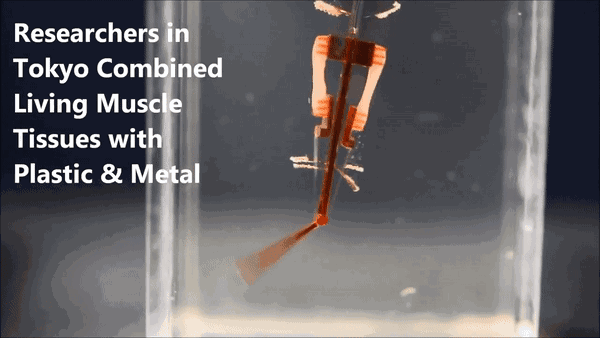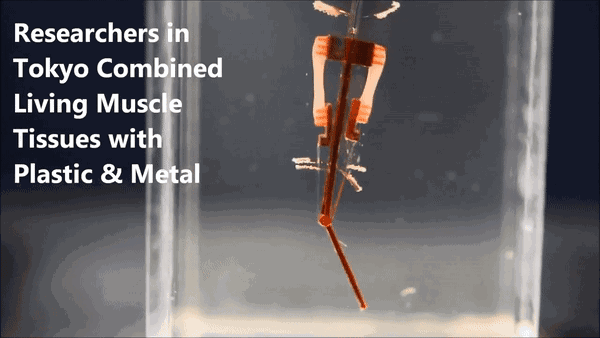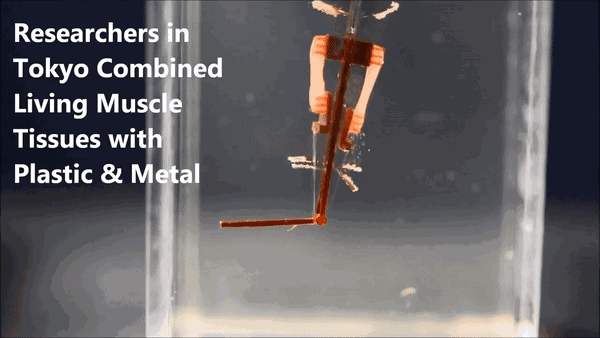
对的,这个来自日本的机械臂采用了"生物混合(biohybrid)"设计,模拟人类手指的结构和功能,用两组大鼠肌肉来控制机械臂关节。
也许叫它"机械指"更合适。
而且,这个使用了活体肌肉的机械指,还能相互协作,提起重量更大的东西。不信你看。

上面这个混搭了活体肌肉的机械臂,出自东京大学的Yuya Morimoto、Hiroaki Onoe和Shoji Takeuchi等人。
如今登上Science Robotics最新一期封面。这足以证明其分量。有报道谈到这个研究时,称之为机器人领域的新突破。

活体机械指如何打造?
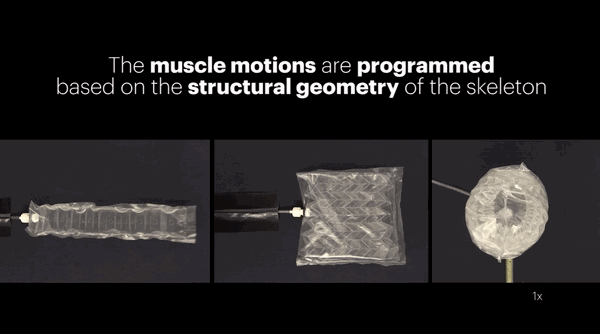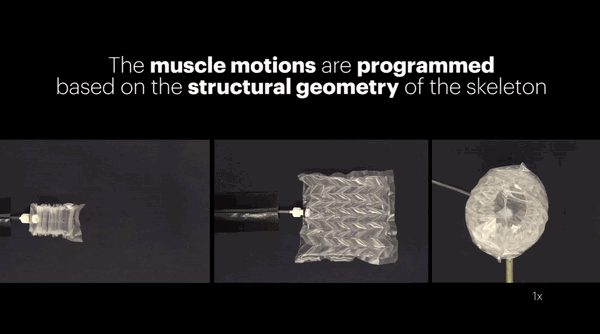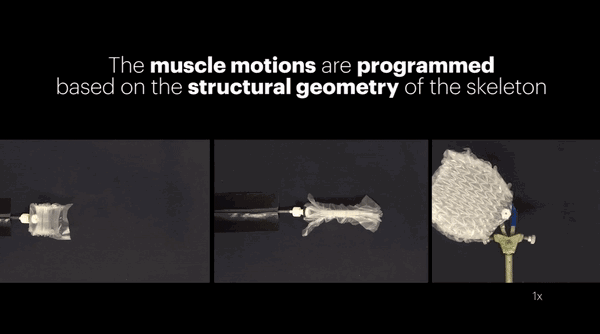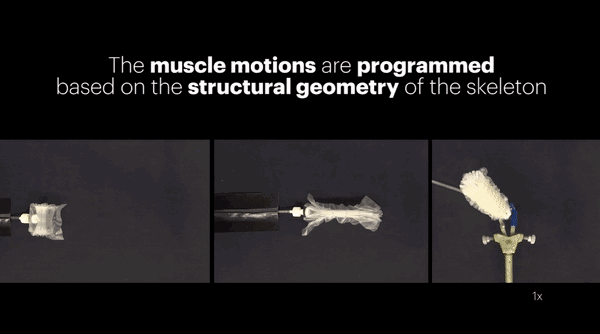
上面这个能直能弯的机械指看起来简陋,内部结构却并不简单,论文中有详细的介绍。
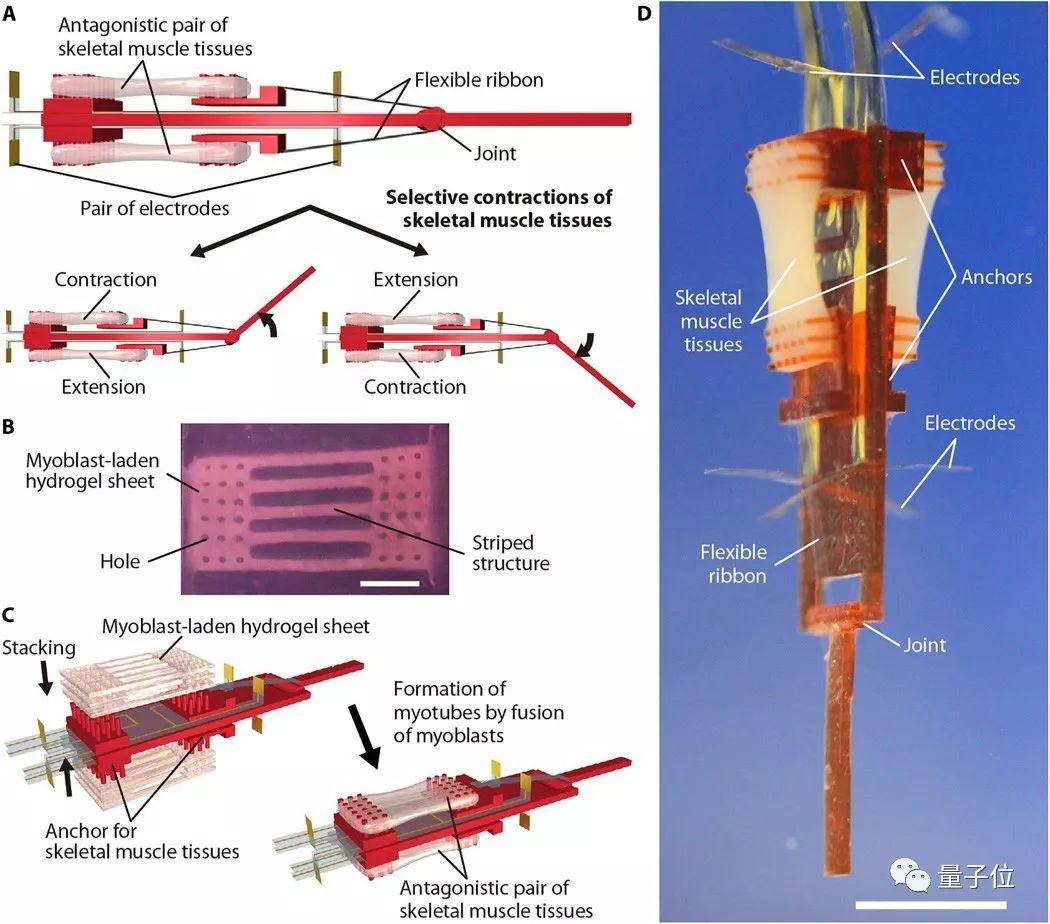
机械指的中心是一根"骨架",带有一个关节,骨架顶端和中间分别有两个电极。在两对电极之间,有四个活动的锚点,上面生长着两组对抗性的活体骨骼肌,下边的两个锚点带有柔性连接带,连到关节的两侧。
肌肉受到电流刺激会收缩,也就带动着关节运动,完成了机械指的弯曲动作。
虽说用到了活体肌肉,但制造过程中并不需要磨刀霍霍向大鼠。这些肌肉是直接从机械指的骨架上"长"出来的。
为了让树脂骨架长出肌肉,科学家们在上面铺满了包裹着成肌细胞(大鼠肌肉细胞)的水凝胶片。
水凝胶片只能保障肌肉长大,却不能一直让它存活下去。所以,这个使用活体肌肉的机械指有一个非常大的局限:只能生活在水里。
这么艰难,为什么还要用活体肌肉呢?
因为机器人通常用的那些塑料、金属之类的材料,无论是运动幅度还是弹性都比肌肉差远了。
一周的寿命
活体肌肉性能好,但真正用到机器人上,就面临这个一个非常现实的问题:一条肌肉能用多久?
这项新研究的答案是:"长达"1周。
论文的作者之一Takeuchi之前就在机器人上用过活体组织,但是,寿命都非常短,用不了几次,肌肉就会收缩到无法工作。
这次,为了延长活体肌肉的寿命,他们使用了一种特殊的结构:让肌肉对抗性成对排列。
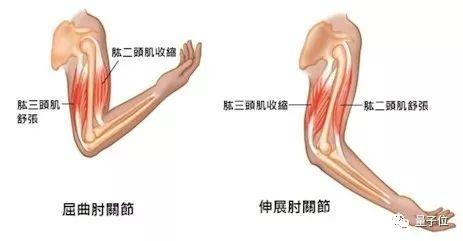
所谓"对抗性",我们胳膊上的肱二头肌、肱三头肌之间,就是这个关系。肱二头肌收缩时,肱三头肌自然就舒张开来,反之亦然。
这种设计,除了延长肌肉的使用寿命之外,还让这个机械臂的关节旋转范围达到了90度。
下一步
这个机械指目前堪称简陋,寿命也就一周,但是在它背后,是制造机器人的一种可行新方法,几位科学家的目标也当然不止于此。
他们接下来,不仅要优化关节结构、延长这种机器人的寿命,也想继续拓展的它的能力。
作者之一、东京大学工程师Takeuchi在接受《国家地理》杂志采访时说:"如果我们能在一台设备中加入更多这样的肌肉,我们就能复制出复杂的肌肉运动,构建像手、胳膊或者人体其他部分一样的机器。"

论文
如果你对这项研究感兴趣,可以前往Science Robotics观摩。传送门:https://ift.tt/2Lbkdij
或者,在量子位公众号(ID:QbitAI)对话界面,回复"肌肉"两个字,即可获得论文的下载地址。
One More Thing
关于为机器人创造"肌肉"这件事,科学家们一直在努力。
例如今年初,科罗拉多大学的学者们宣布正在研发和人类肌肉一样,具有自愈能力的人造肌肉。而且造价只需10美分。
这种机器肌肉学名是:液压放大自愈式静电致动器(HASEL)。这个技术未来有望简化庞大的金属机器人,并让他们能更好的模仿人类动作。

这个人造肌肉是由植物油、水凝胶电极填充的小袋构成。通电之后,电极周围的油会产生收缩,而断电之后,机器肌肉会放松下来。
整个收缩过程在毫秒内完成,丝毫不虚人类肌肉。
这项研究,也发表在Science和Science Robotics上。传送门:
https://ift.tt/2F2Umqz
https://ift.tt/2EbxrIf
去年底,哈佛和MIT携手合作,也开发了一个强大又廉价的人造肌肉。这个看起来软趴趴的东西,能提起比自身重1000倍的物体。
原理嘛,据说是受到折纸的启发。
这项研究发表在PNAS上,感兴趣的话,可以前往观摩学习。传送门:https://ift.tt/2zzgiGw
就酱。
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


























 ▲ 图2:在CIFAR-10和CIFAR-100上的测试结果
▲ 图2:在CIFAR-10和CIFAR-100上的测试结果




