作者 | 迪迦
编辑 | 陈大鑫
元学习容易受到对抗攻击吗?这篇论文在小样本(few-shot)分类的问题下,对元学习中的对抗攻击进行了初步的研究。一系列实验结果表明,本文所提出的攻击策略可以轻松破解元学习器,即元学习是容易受到攻击的。
本文作者来自密西根州立大学的汤继良团队,汤继良是密歇根州立大学数据科学与工程实验室(Data Science and Engineering Laboratory)教授,于今年8月刚刚荣获新设立的第一届KDD年度新星奖(Rising Star Award)。
论文链接:https://ift.tt/3c5JKIx
本文动机
元学习算法的成功促进了其在许多关键安全任务中的应用,包括人脸识别、物体检测和模仿学习。然而,元学习算法的可靠性和鲁棒性问题却很少被研究,这使得基于元学习的技术应用面临着很大的潜在风险,特别是在存在敌对攻击者的情况下。
如上图所示,对于小样本分类任务,在元学习测试阶段,攻击可以在元学习测试任务
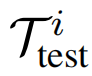 中对
中对
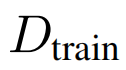 的一个训练样本插入不明显的扰动,导致其在
的一个训练样本插入不明显的扰动,导致其在
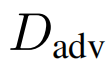 上训练的自适应模型精度大大降低。
上训练的自适应模型精度大大降低。
本文致力于研究元学习的鲁棒性问题,重点探索其在小样本分类问题中的应用。本文的主要贡献可以总结如下:
-
第一次正式定义了攻击元学习算法的关键要素,包括对抗目标( adversarial goal)和不可察觉的扰动(unnoticeable perturbation)。 -
在新定义的扰动约束下,提供了一种新的目标函数表达式,用于针对目标攻击和非针对目标攻击的元学习攻击。 -
提出了一种新的元学习攻击算法-元攻击器(MetaAttacker)来优化所提出的目标函数,使对抗样本能够有效地计算出复杂多样的受害者模型结构。 -
通过不同的元学习框架,包括 MAML、SNAIL 和 Prototypical,系统地评估了元学习的可靠性和鲁棒性。
威胁模型的建立
在本节中,作者详细描述了提出的元学习威胁模型的关键组成部分,包括受害者模型(victim model)、对抗目标和不可察觉的扰动。
A.元学习器受害者
一般来说,不同的元学习算法都有其独特的元学习结构。这里简要介绍了三个具有代表性的受害者元学习器。
1、基于优化的元学习器:如 MAML 通常会模拟优化的过程,其中,自适应模型的参数被更新,从而能够在任务
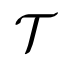 上获得最小的损失,并使用了相关的训练数据
上获得最小的损失,并使用了相关的训练数据
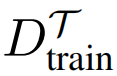 。例如,MAML 通过运行 m 个梯度下降步骤生成一个自适应的模型
。例如,MAML 通过运行 m 个梯度下降步骤生成一个自适应的模型
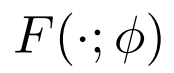 :
:
其中 α 是步长,元学习器的参数 θ 作为模型
的初始化参数。
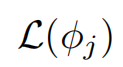 表示
上
的总训练损失:
表示
上
的总训练损失:
元学习器希望通过最小化训练损失,在测试样本
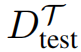 中得到一个误差较小的
模型。MAML 模型在任务
上的性能依赖于模型初始化参数 θ 和梯度。稍后,我们将讨论攻击者如何操纵训练样本来误导MAML使用“恶意”的梯度进行更新。
中得到一个误差较小的
模型。MAML 模型在任务
上的性能依赖于模型初始化参数 θ 和梯度。稍后,我们将讨论攻击者如何操纵训练样本来误导MAML使用“恶意”的梯度进行更新。
2、基于模型的元学习器:MANN 和 SNAIL 等基于模型的元学习器作为 DNN 模型,从
中获取输入,直接输出自适应模型
。
3、基于度量的元学习器:基于度量的元学习器通常由两部分组成:一部分是用于特征提取的 DNN 模型,它将所有的训练样本和测试样本投影到一个特征空间;另一部分是将特征空间划分为不同类别的分类器。
B:对抗目标
元学习攻击的主要目标是误导元学习器产生“恶意”模型,这与传统的以测试为中心的对抗性攻击不同。因此,我们需要正式重新定义元学习攻击的对抗目标。本文在白盒攻击下考虑两种不同类型的对抗目标来欺骗元学习器,包括非针对目标攻击和针对目标攻击。
注:针对目标攻击:攻击者在构造对抗样本时欺骗目标模型,将对抗样本错分到指定分类类别。非针对目标攻击:对抗样本的预测标记是不相关的,只需让目标模型将其错误分类, 即除了原始类别,对抗类输出可以是任意的。
1、非针对目标攻击:在非针对目标攻击的情况下,对抗的目的是让自适应分类器
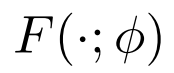 在任务
的测试样本中具有较差的整体性能(低精度)。该对抗目标可以表述为找到一个对抗性数据集
,最大限度地提高自适应模型的测试损失:
在任务
的测试样本中具有较差的整体性能(低精度)。该对抗目标可以表述为找到一个对抗性数据集
,最大限度地提高自适应模型的测试损失:
1、针对目标攻击:针对目标攻击下的对抗以测试样本的某个子集
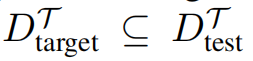 作为目标样本,旨在破坏自适应模型在这些目标样本上的性能。具体地说,本文将来自一个特定类的所有样本视为任务
中的目标样本。形式上,对于 t 类目标,本文将针对目标攻击的目标定义为:
作为目标样本,旨在破坏自适应模型在这些目标样本上的性能。具体地说,本文将来自一个特定类的所有样本视为任务
中的目标样本。形式上,对于 t 类目标,本文将针对目标攻击的目标定义为:
1、代替测试误差:在非针对目标攻击和针对目标攻击中,攻击者都需要知道测试样本
,这在现实场景中是不现实的。因此,本文建议使用训练样本
的经验训练损失来近似测试损失。在进行元学习对抗攻击时,我们希望所提出的基于扰动训练集的模型能够将“恶意”知识推广到不可见的测试样本中。在形式上,本文将非针对目标和针对目标统一如下:
其中
在针对目标攻击的情况下其实是
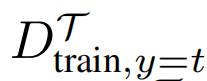 。
。
C:不明显的扰动
在元学习攻击中,不可察觉的扰动也是一个值得关注的问题,但如何定义这种环境下的不可察觉的扰动还没有确定。在这项工作中,本文提供两个原则,即扰动样本预算和感知相似性,以确保扰动数据集
与
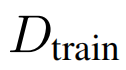 相似。
相似。
1、扰动样本预算:为了达到对抗目标,要求对抗扰动尽可能少的样本,因为对抗注入系统的假样本越少,检测到这种攻击的可能性就越小。本文把
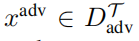 表示为扰动集
表示为扰动集
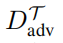 中的扰动样本,
中的扰动样本,
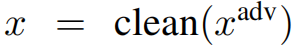 作为相应的干净样本。形式上,定义扰动样本预算受 k 的限制:
作为相应的干净样本。形式上,定义扰动样本预算受 k 的限制:
1、感知相似性:在每个单独的扰动样本中,我们要求扰动图像在感知上与干净图像相似。换句话说,我们增加的扰动对人类来说是无法区分的。本文通过如下限制扰动来达到这一标准:
元学习攻击
根据上一节所述的攻击目标和攻击能力,可以将元学习攻击问题定义如下:
问题 1:给定一个训练好的元学习器
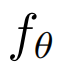 ,一个新的未知学习任务
,相应的训练样本
和扰动预算
,一个新的未知学习任务
,相应的训练样本
和扰动预算
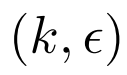 ,我们的目标是通过解决以下优化问题来找到一个对抗性训练集
,我们的目标是通过解决以下优化问题来找到一个对抗性训练集
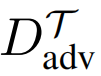 :
:
换言之,在问题 1 中,我们的目标是用范数
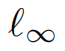 扰动动约束
扰动动约束
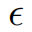 以及对训练数据集
中的最多 k 个样本进行扰动。在
中选择要扰动的样本是一个组合优化问题,本文为这类选择过程提供了一个贪婪算法,如图 2 所示。在此之前,首先描述了元学习攻击算法,并为给定的选择集
以及对训练数据集
中的最多 k 个样本进行扰动。在
中选择要扰动的样本是一个组合优化问题,本文为这类选择过程提供了一个贪婪算法,如图 2 所示。在此之前,首先描述了元学习攻击算法,并为给定的选择集
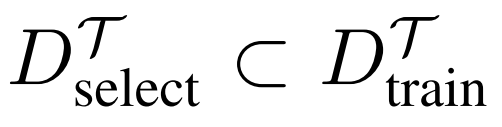 生成对抗性样本,如下图所示。
生成对抗性样本,如下图所示。
通过链式法则计算样本
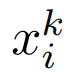 的梯度:
的梯度:
其中,
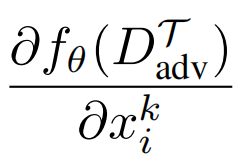 表示计算图的雅可比矩阵计算。文中以 MAML 模型为例展示了以上流程,如下图所示:
表示计算图的雅可比矩阵计算。文中以 MAML 模型为例展示了以上流程,如下图所示:
最后,我们还需要搜索最优的对抗集。作者提供了一个贪婪的算法来获得一个近似解,以持续地将最危险的对抗样本加入攻击包中。算法流程如下图所示:
在每个迭代 i 中,我们从
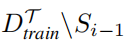 中选择一个样本
中选择一个样本
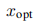 ,当将其添加到集合
,当将其添加到集合
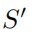 中时,它会导致最大的对抗损失
中时,它会导致最大的对抗损失
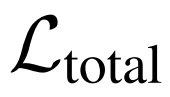 。这样,我们通过构造最具对抗性的 1-set,2-set 直到 k-set 扰动,迭代地扩大我们的候选集。
。这样,我们通过构造最具对抗性的 1-set,2-set 直到 k-set 扰动,迭代地扩大我们的候选集。
实验部分
在本节中,作者针对三种流行的元学习算法,包括 MAML、SNAIL 和原型网络,对所提出的元学习攻击算法进行了评估。论文首先讨论了 MAML 模型的全部结果,以全面了解其在不同设置下的鲁棒性。然后,作者又对 SNAIL 和原型网络进行了攻击,以研究不同元学习结构之间的差异。
A:实验设置
数据集选取:作者将所提出的元学习攻击算法应用于两个最常用的基准数据集(包括 Omniglot 和 MiniImagenet 数据集)上的小样本学习问题。
不明显的扰动:对于 Omniglot 数据集,它由像素分辨率为 28×28 的手写字符图像组成,像素分辨率在[0,1]范围内,这与 MNIST 相似。因此,通过限制不大于 0.3 的
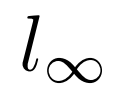 范数:
范数:
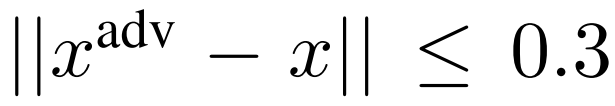 ,我们就将此数据集中的扰动定义为不可察觉的。对于图像大小为 84×84 的 MiniImagenet 数据集,我们通过限制
,我们就将此数据集中的扰动定义为不可察觉的。对于图像大小为 84×84 的 MiniImagenet 数据集,我们通过限制
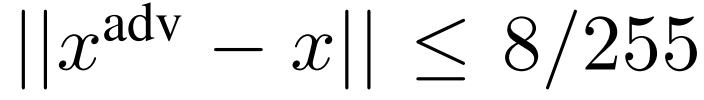 来约束不可察觉的扰动。一般来说,对于一个 5-way 5-shot 分类问题,我们将限制扰动预算为:在 25 个训练样本(每个类五个样本)中攻击者不能攻击超过 1、2、3 或 5 幅图像。
来约束不可察觉的扰动。一般来说,对于一个 5-way 5-shot 分类问题,我们将限制扰动预算为:在 25 个训练样本(每个类五个样本)中攻击者不能攻击超过 1、2、3 或 5 幅图像。
B:MAML 实验结果
1、清洁性能:表 1 显示了模型在不同微调步骤(m =1,5,10)下的清洁性能。从表 2 可以看出,更多精细的调优步骤将有助于提高 MAML 在 Omniglot 和 MiniImageNet 中的清洁性能。
1、非针对目标攻击性能
论文研究了非针对目标攻击算法的性能,该算法旨在影响自适应分类模型的总体精度。作者在 100 个测试任务 {
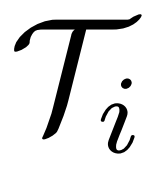 ,i =1,2,…,100} 中评估了自适应模型的平均精度。除了不同扰动预算下的攻击结果外,作者还给出了两种基线性能。Non-attack表示MAML在所有选定任务中的清洁测试性能。Random F.T.意味着对于每个任务
,随机初始化模型参数
,i =1,2,…,100} 中评估了自适应模型的平均精度。除了不同扰动预算下的攻击结果外,作者还给出了两种基线性能。Non-attack表示MAML在所有选定任务中的清洁测试性能。Random F.T.意味着对于每个任务
,随机初始化模型参数
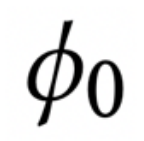 ,并从这个随机的
进行微调。由于 MAML 本质上是要为任务
找到一个合适的初始化,所以使用 Random F.T.来显示学习过程没有来自 MAML 的指导的情况。
,并从这个随机的
进行微调。由于 MAML 本质上是要为任务
找到一个合适的初始化,所以使用 Random F.T.来显示学习过程没有来自 MAML 的指导的情况。
在表 1 中,我们注意到在随机样本上产生随机噪声几乎不会影响 MAML 的性能。对于 MiniImagenet 数据集,最成功的攻击案例(当 MAML 进行 1 步微调时修改 10 个样本)将平均准确率从 63.3%降低到 16.2%。最困难的攻击设置(在 10 步微调下修改 1 个样本)也可以将整体准确率从 65.2%降低到 56.6%。对于 Omniglot 数据集,一个攻击需要扰动至少 2 个样本才能使元学习器的性能降低 2∼5%,而扰动5个样本则会使元学习器的表现降低20%。
2、针对目标攻击性能
在这一小节中,我们不去观察元学习者的总体鲁棒性表现,而是通过一个局部的观点来研究元学习器的鲁棒性,即定位于每个学习任务的一个单独的类别。在实验中,作者考虑了以下两种设置:
(1)直接攻击:对手可以操纵目标类的样本,即
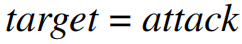 ;
;
(2)影响力攻击:攻击只能操纵不同类的训练样本,即
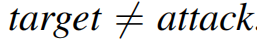 。
。
结果如下图所示,直接攻击和影响力攻击都达到了对抗性的目的,以影响自适应模型对目标类别的性能。
C: 攻击其他元学习模型
除了 MAML,本文还考虑了另外两种其他类型的元学习模型,包括一种基于模型的元学习器 SNAIL 和一种基于度量的元学习器原型网络。
如下图(a)所示,这两种元学习模型也容易受到非针对目标的对抗攻击,并且随着扰动预算的增加,平均性能显著下降。对于图(b)和(c)所示的针对目标攻击,SNAIL 模型很容易受到直接攻击和影响攻击。然而,对于原型网络,直接攻击会导致目标样本的性能大幅下降,而影响攻击对目标样本几乎没有影响。
总结
在这项工作中,作者首先正式定义了元学习算法的对抗性攻击和鲁棒性问题。基于这个定义,作者设计了有效的攻击方法来实现目标,并针对不同的元学习模型在不同的数据集上验证了方法。实验结果表明,元学习攻击会导致这些元学习模型的性能显著下降。这项研究为元学习的安全问题打开了大门。
[赠书福利]
在AI科技评论9月11日推文“《柏拉图与技术呆子》:探讨人类与技术的创造性伙伴关系”留言区留言,谈一谈你对本书的相关看法、期待等。
AI 科技评论将会在留言区选出5名读者,每人送出《柏拉图与技术呆子》一本。
活动规则:
1. 在留言区留言,留言点赞最高且留言质量较高的前 5 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容和留言质量会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年9月11日 - 2020年9月18日(23:00),活动推送内仅允许中奖一次。
EMNLP 9月16日出录用结果了!
扫描下方二维码,加入学习交流群!
点击阅读原文加入“EMNLP”小组!

没有评论:
发表评论