介绍 描述最常用的RNN实现方式:Long-Short Term Memory (LSTM)
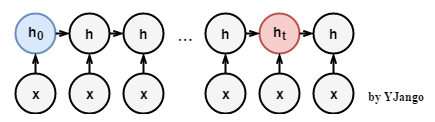
梯度消失和梯度爆炸 网络回忆: 在《循环神经网络 ——介绍》 中提到循环神经网络 用相同的方式处理每个时刻的数据。
数学公式 : 设计目的: 我们希望循环神经网络 可以将过去时刻发生的状态信息传递给当前时刻的计算中。
实际问题: 但普通的RNN结构却难以传递相隔较远的信息。
考虑: 若只看上图蓝色箭头线的、隐藏状态的传递过程,不考虑非线性部分,那么就会得到一个简化的式子(1): (1) 如果将起始时刻的隐藏状态信息 (2) 特征分解 (3) 式子(2)会变成(4) (4) 当特征值小于1时,不断相乘的结果是特征值的
Long Short Term Memory (LSTM) 上面的现象可能并不意味着无法学习,但是即便可以,也会非常非常的慢。为了有效的利用梯度下降 法学习,我们希望使不断相乘的梯度的积(the product of derivatives)保持在接近1的数值。
一种实现方式是建立线性自连接单元(linear self-connections)和在自连接部分数值接近1的权重 ,叫做leaky units。但Leaky units的线性自连接权重 是手动设置或设为参数 ,而目前最有效的方式gated RNNs是通过gates的调控,允许线性自连接的权重 在每一步都可以自我变化调节。 LSTM就是gated RNNs中的一个实现。
LSTM的初步理解 LSTM(或者其他gated RNNs)是在标准RNN (神经网络 (RNN整体)中加入其他神经网络 (gates),而这些gates只是控制数级,控制信息的流动量 。
数学公式: 这里贴出基本LSTM的数学公式,看一眼就好,仅仅是为了让大家先留一个印象,不需要记住,不需要理解。
尽管式子不算复杂,却包含很多知识,接下来就是逐步分析这些式子以及背后的道理。 比如
门(gate)的理解 理解Gated RNNs的第一步就是明白gate到底起到什么作用。
物理意义 :gate本身可看成是十分有物理意义的一个神经网络 。 输入:gate的输入是控制依据; 输出:gate的输出是值域为 使用方式 :gate所产生的输出会用于控制其他数据的数级,相当于过滤器的作用。类比图:可以把信息想象成水流,而gate就是控制多少水流可以流过。 例如:当用gate来控制向量 若gate的输出为
若gate的输出为
控制依据 :明白了gate的输出后,剩下要确定以什么信息为控制依据,也就是什么是gate的输入。 例如:即便是LSTM也有很多个变种。一个变种方式是调控门的输入。例如下面两种gate: 这种gate的输入有当前的输入 这种gate的输入有当前的输入 LSTM的再次理解 明白了gate之后再回过头来看LSTM的数学公式
数学公式 :
gates: 先将前半部分的三个式子 注: 虽然gates的式子构成方式一样,但是注意3个gates式子权重 。 有了这3个gates后,接下来要考虑的就是如何用它们装备在普通的RNN上来控制信息流,而根据它们所用于控制信息流通的地点不同,它们又被分为: 输入门 遗忘门 输出门 注:gates并不提供额外信息,gates只是起到限制信息的量的作用。因为gates起到的是过滤器作用,所以所用的激活函数 是sigmoid而不是tanh。 信息流: 信息流的来源只有三处,当前的输入 分析了gates和信息流后,再分析剩下的两个等式,来看LSTM是如何累积历史信息和计算隐藏状态 历史信息累积: 所以历史信息的累积是并不是靠隐藏状态
当前隐藏状态的计算: 如此大费周章的最终任然是同普通RNN一样要计算当前隐藏状态。 式子: 当前隐藏状态 普通RNN与LSTM的比较 下面为了加深理解循环神经网络 的核心,再来和YJango一起比较一下普通RNN和LSTM的区别。
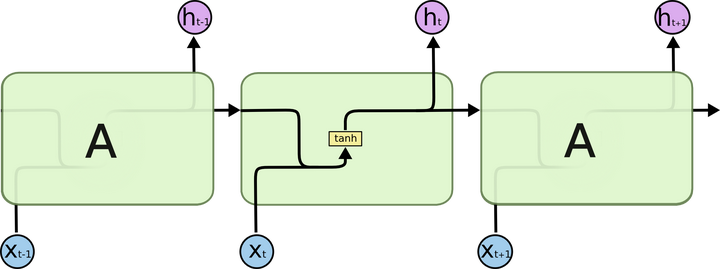
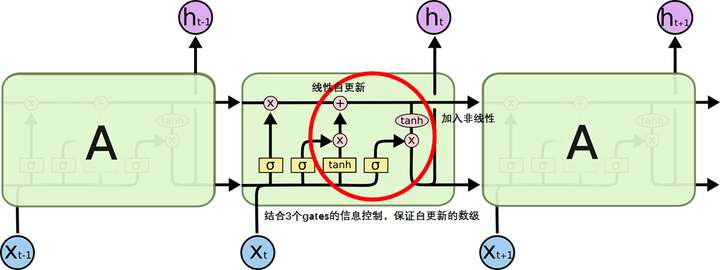
比较公式: 最大的区别是多了三个神经网络 (gates)来控制数据的流通。 普通RNN: LSTM: 比较: 二者的信息来源都是 不同的是LSTM靠3个gates将信息的积累建立在线性自连接的memory cell之上,并靠其作为中间物来计算当前 示图比较: 图片来自Understanding LSTM ,强烈建议一并阅读。 LSTM: 加号圆圈表示线性相加,乘号圆圈表示用gate来过滤信息。 比较: 新信息从黄色的tanh处,线性累积到memory cell之中后,又从红色的tanh处加入非线性并返回到了隐藏状态 LSTM靠3个gates将信息的积累建立在线性自连接的权重 接近1的memory cell之上,并靠其作为中间物来计算当前 LSTM的类比 对于用LSTM来实现RNN的记忆,可以类比我们所用的手机(仅仅是为了方便记忆,并非一一对应)。
普通RNN好比是手机屏幕,而LSTM-RNN好比是手机膜。
大量非线性累积历史信息会造成梯度消失(梯度爆炸)好比是不断使用后容易使屏幕刮花。
而LSTM将信息的积累建立在线性自连接的memory cell之上,并靠其作为中间物来计算当前
输入门、遗忘门、输出门的过滤作用好比是手机屏幕膜的反射率、吸收率、透射率三种性质。
Gated RNNs的变种 需要再次明确的是,神经网络 之所以被称之为网络是因为它可以非常自由的创建合理的连接。而上面所介绍的LSTM也只是最基本的LSTM。只要遵守几个关键点,读者可以根据需求设计自己的Gated RNNs,而至于在不同任务上的效果需要通过实验去验证。下面就简单介绍YJango所理解的几个Gated RNNs的变种的设计方向。
信息流 :标准的RNN的信息流有两处:input输入和hidden state隐藏状态。 但往往信息流并非只有两处,即便是有两处,也可以拆分成多处,并通过明确多处信息流之间的结构关系来加入先验知识 ,减少训练所需数据量,从而提高网络效果。
例如:Tree-LSTM 在具有此种结构的自然语言处理 任务中的应用。
gates的控制方式 :与LSTM一样有名的是Gated Recurrent Unit (GRU),而GRU使用gate的方式就与LSTM的不同,GRU只用了两个gates,将LSTM中的输入门和遗忘门合并成了更新门。并且并不把线性自更新建立在额外的memory cell上,而是直接线性累积建立在隐藏状态上,并靠gates来调控。 gates的控制依据 :上文所介绍的LSTM中的三个gates所使用的控制依据都是 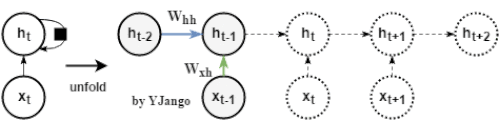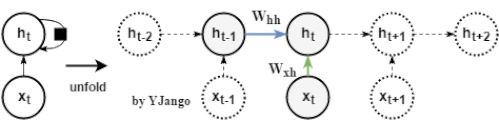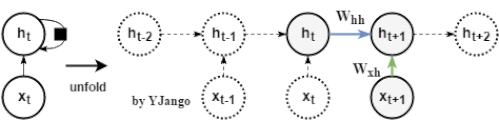


 向第
向第 时刻传递,会得到式子(2)
时刻传递,会得到式子(2)
 会被乘以多次,若允许矩阵
会被乘以多次,若允许矩阵 进行特征分解
进行特征分解 

 次方向
次方向  衰减; 当特征值大于1时,不断相乘的结果是特征值的t次方向
衰减; 当特征值大于1时,不断相乘的结果是特征值的t次方向  扩增。 这时想要传递的
扩增。 这时想要传递的 中的信息会被掩盖掉,无法传递到
中的信息会被掩盖掉,无法传递到 。
。
 ,如果
,如果 等于0.1,
等于0.1, 在被不断乘以0.1一百次后会变成多小?如果
在被不断乘以0.1一百次后会变成多小?如果 等于5,
等于5, 在被不断乘以5一百次后会变得多大?若想要
在被不断乘以5一百次后会变得多大?若想要 所包含的信息既不消失,又不爆炸,就需要尽可能的将
所包含的信息既不消失,又不爆炸,就需要尽可能的将 的值保持在1。
的值保持在1。 )的基础上装备了若干个控制数级(magnitude)的gates。可以理解成神经网络(RNN整体)中加入其他神经网络(gates),而这些gates只是控制数级,控制信息的流动量。
)的基础上装备了若干个控制数级(magnitude)的gates。可以理解成神经网络(RNN整体)中加入其他神经网络(gates),而这些gates只是控制数级,控制信息的流动量。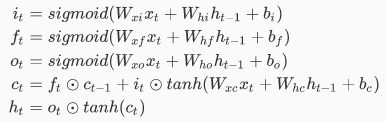
 的意义和使用原因,sigmoid的使用原因。
的意义和使用原因,sigmoid的使用原因。 的数值,表示该如何调节其他数据的数级的控制方式。
的数值,表示该如何调节其他数据的数级的控制方式。
![\left[\begin{matrix}20 & 5& 7 & 8 \\\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/f05c87ac-f7ae-40ae-a7c2-bf2e56f79895/1534236723289.png) 时,
时,![\left[\begin{matrix}0.1 & 0.2& 0.9 & 0.5 \\\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/93e27c78-2491-4875-8bad-2973e9702d10/1534236723014.png) 时,原来的向量就会被对应元素相乘(element-wise)后变成:
时,原来的向量就会被对应元素相乘(element-wise)后变成:![\left[\begin{matrix}20 & 5& 7 & 8 \\\end{matrix}\right]\odot \left[\begin{matrix}0.1 & 0.2& 0.9 & 0.5 \\\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/a39eb91d-12f3-46f2-adf4-ba2ff80595b0/1534236723396.png) =
=![\left[\begin{matrix}20*0.1 & 5*0.2& 7*0.9 & 8*0.5 \\\end{matrix}\right]=\left[\begin{matrix}2 & 1& 6.3 & 4 \\\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/8443cac6-f770-4f8d-a36a-e100856d1954/1534236723492.png)
![\left[\begin{matrix}0.5 & 0.5& 0.5 & 0.5 \\\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/93a46348-87b6-4bdf-a735-71d40db68652/1534236723594.png) 时,原来的向量就会被对应元素相乘(element-wise)后变成:
时,原来的向量就会被对应元素相乘(element-wise)后变成:![\left[\begin{matrix}20 & 5& 7 & 8 \\\end{matrix}\right]\odot \left[\begin{matrix}0.5 & 0.5& 0.5 & 0.5 \\\end{matrix}\right]=\left[\begin{matrix}10 & 2.5& 3.5 & 4 \\\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/80293db1-0502-4a71-931d-8ff3c8db494e/1534236723641.png)
 :
: 和上一时刻的隐藏状态
和上一时刻的隐藏状态 , 表示gate是将这两个信息流作为控制依据而产生输出的。
, 表示gate是将这两个信息流作为控制依据而产生输出的。 :
: 和上一时刻的隐藏状态
和上一时刻的隐藏状态 ,以及上一时刻的cell状态
,以及上一时刻的cell状态 , 表示gate是将这三个信息流作为控制依据而产生输出的。这种方式的LSTM叫做peephole connections。
, 表示gate是将这三个信息流作为控制依据而产生输出的。这种方式的LSTM叫做peephole connections。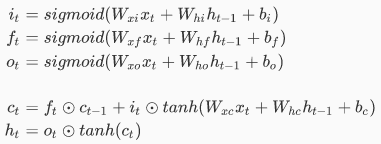
 统一理解。在LSTM中,网络首先构建了3个gates来控制信息的流通量。
统一理解。在LSTM中,网络首先构建了3个gates来控制信息的流通量。 和
和 的下角标并不相同。它们有各自的物理意义,在网络学习过程中会产生不同的权重。
的下角标并不相同。它们有各自的物理意义,在网络学习过程中会产生不同的权重。 :控制有多少信息可以流入memory cell(第四个式子
:控制有多少信息可以流入memory cell(第四个式子 )。
)。 :控制有多少上一时刻的memory cell中的信息可以累积到当前时刻的memory cell中。
:控制有多少上一时刻的memory cell中的信息可以累积到当前时刻的memory cell中。 :控制有多少当前时刻的memory cell中的信息可以流入当前隐藏状态
:控制有多少当前时刻的memory cell中的信息可以流入当前隐藏状态 中。
中。 ,上一时刻的隐藏状态
,上一时刻的隐藏状态 ,上一时刻的cell状态
,上一时刻的cell状态 ,其中
,其中 是额外制造出来、可线性自连接的单元(请回想起leaky units)。真正的信息流来源可以说只有当前的输入
是额外制造出来、可线性自连接的单元(请回想起leaky units)。真正的信息流来源可以说只有当前的输入 ,上一时刻的隐藏状态
,上一时刻的隐藏状态 两处。三个gates的控制依据,以及数据的更新都是来源于这两处。
两处。三个gates的控制依据,以及数据的更新都是来源于这两处。 的。
的。
 是本次要累积的信息来源。
是本次要累积的信息来源。
 自身,而是依靠memory cell这个自连接来累积。 在累积时,靠遗忘门来限制上一时刻的memory cell的信息,并靠输入门来限制新信息。并且真的达到了leaky units的思想,memory cell的自连接是线性的累积。
自身,而是依靠memory cell这个自连接来累积。 在累积时,靠遗忘门来限制上一时刻的memory cell的信息,并靠输入门来限制新信息。并且真的达到了leaky units的思想,memory cell的自连接是线性的累积。
 是从
是从 计算得来的,因为
计算得来的,因为 是以线性的方式自我更新的,所以先将其加入带有非线性功能的
是以线性的方式自我更新的,所以先将其加入带有非线性功能的 。 随后再靠输出门
。 随后再靠输出门 的过滤来得到当前隐藏状态
的过滤来得到当前隐藏状态 。
。

 , 不同的是LSTM靠3个gates将信息的积累建立在线性自连接的memory cell之上,并靠其作为中间物来计算当前
, 不同的是LSTM靠3个gates将信息的积累建立在线性自连接的memory cell之上,并靠其作为中间物来计算当前 。
。 
 的计算中。
的计算中。 。
。
 好比是用手机屏幕膜作为中间物来观察手机屏幕。
好比是用手机屏幕膜作为中间物来观察手机屏幕。
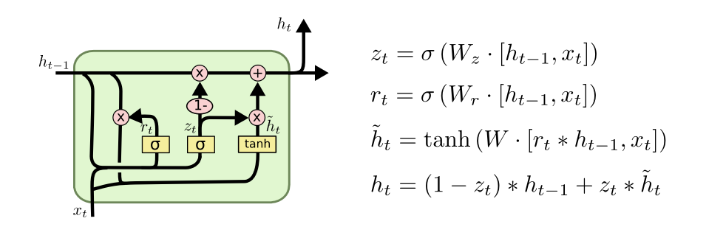
 ,但是可以通过与memory cell的连接来增加控制依据或者删除某个gate的
,但是可以通过与memory cell的连接来增加控制依据或者删除某个gate的 或
或 来缩减控制依据。比如去掉上图中
来缩减控制依据。比如去掉上图中![z_t=sigmoid(W_z\cdot [h_{t-1},x_t])](https://image.jiqizhixin.com/uploads/editor/ff5eb079-2035-4f2b-8e90-182d3c155bb8/1534236727864.png) 中的
中的 从而变成
从而变成

没有评论:
发表评论