深层神经网络相比一般的统计学习拥有从数学的严谨中不会得出的关于物理世界的先验知识(非贝叶斯先验)。该内容也在Bengio大神的论文和演讲中多次强调。大神也在Bay Area Deep Learning School 2016的Founda'ons and Challenges of Deep Learning pdf(这里也有视频,需翻墙)中提到的distributed representations和compositionality两点就是神经网络和深层神经网络高效的原因(若有时间,强烈建议看完演讲再看该文)。虽然与大神的思考起点可能不同,但结论完全一致(看到Bengio大神的视频时特别兴奋)。下面就是结合例子分析: 1. 为什么神经网络高效 2. 学习的本质是什么 3. 为什么深层神经网络比浅层神经网络更高效 4. 神经网络在什么问题上不具备优势
其他推荐读物
Bengio Y. Learning deep architectures for AI[J]. Foundations and trends® in Machine Learning, 2009, 2(1): 1-127.
Brahma P P, Wu D, She Y. Why Deep Learning Works: A Manifold Disentanglement Perspective[J]. 2015.
Lin H W, Tegmark M. Why does deep and cheap learning work so well?[J]. arXiv preprint arXiv:1608.08225, 2016.
Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(8): 1798-1828.

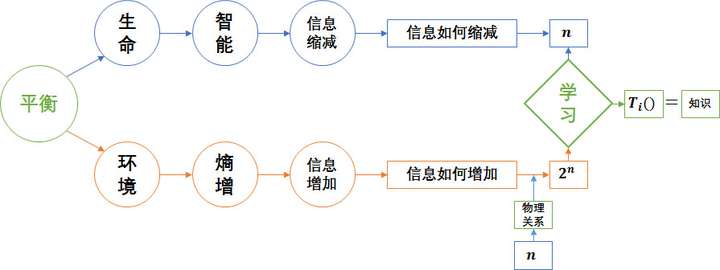
 )转化回因素(
)转化回因素( )附带物理关系的形式,从源头消除熵(假设每个因素只有两种可能状态)。这样所有状态间的关系可以被确定,要么肯定发生,要么绝不发生,也就无需用概率来衡量。因此下面定义的学习目标并非单纯降低损失函数,而从确定关系的角度考虑。一个完美训练好的模型就是两个状态空间内所有可能取值间的关系都被确定的模型。
)附带物理关系的形式,从源头消除熵(假设每个因素只有两种可能状态)。这样所有状态间的关系可以被确定,要么肯定发生,要么绝不发生,也就无需用概率来衡量。因此下面定义的学习目标并非单纯降低损失函数,而从确定关系的角度考虑。一个完美训练好的模型就是两个状态空间内所有可能取值间的关系都被确定的模型。



 ,
,  表示sigmoid函数。(只要是非线性即可,relu是目前的主流)
表示sigmoid函数。(只要是非线性即可,relu是目前的主流) 才会为零。
才会为零。 表示
表示 时的熵
时的熵 就会增加。(
就会增加。( 无法照顾到8个关系,若完美拟合一个关系,其余的关系就不准确)
无法照顾到8个关系,若完美拟合一个关系,其余的关系就不准确) 用表示
用表示 的缩写。
的缩写。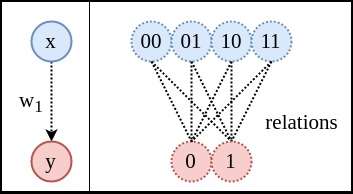
 数据来记住想要拟合的
数据来记住想要拟合的 。
。 把A中的状态分解开(disentangle)。分解成两个独立的子随机变量
把A中的状态分解开(disentangle)。分解成两个独立的子随机变量 和
和 。也就是用二维向量表示输入。
。也就是用二维向量表示输入。 将随机变量
将随机变量 无损转变为
无损转变为 和
和 的共同表达(representation)。这时
的共同表达(representation)。这时 和
和 一起形成网络输入。
一起形成网络输入。
 写成了矩阵的表达形式
写成了矩阵的表达形式 ,其中
,其中 是标量,而
是标量,而![W_{h}=\left[ \begin{matrix} w_{h1}&w_{h2} \end{matrix} \right]](https://image.jiqizhixin.com/uploads/editor/a87d95e3-9dc2-4269-8e99-aa826c5f56bf/1534141883920.png) ,
,![\vec{h}=\left[\begin{matrix}h_{1}\\h_{2}\end{matrix}\right]](https://image.jiqizhixin.com/uploads/editor/835a8645-afdf-4606-a04d-c94a01aa5fec/1534141882998.png)
 固定,只考虑下半部分的关系。因为这时用了两条线
固定,只考虑下半部分的关系。因为这时用了两条线 和
和 来共同对应关系。原本需要拟合的8个关系,现在变成了4个(两个节点平摊)。同样,除非右图的4条红色关系线对
来共同对应关系。原本需要拟合的8个关系,现在变成了4个(两个节点平摊)。同样,除非右图的4条红色关系线对 来说相同,并且4条绿色关系线对
来说相同,并且4条绿色关系线对 来说也相同,否则用
来说也相同,否则用 和
和 表示
表示 时,一定会造成熵
时,一定会造成熵 增加。
增加。 需要表示右侧的4条红色关系线。
需要表示右侧的4条红色关系线。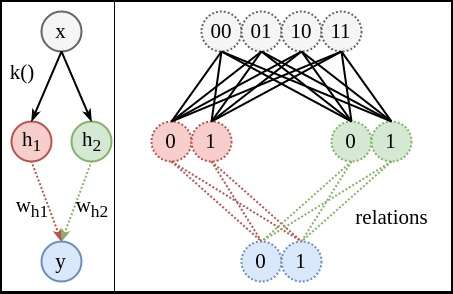
 或者
或者 的值,那么该结构可以轻松用两条线
的值,那么该结构可以轻松用两条线 和
和 来表达这4个关系(让其中一条线的权重为0,另一条为1)。
来表达这4个关系(让其中一条线的权重为0,另一条为1)。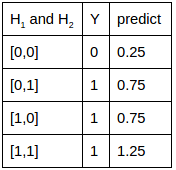
 表达,该网络结构连XOR关联的分类都无法分开。
表达,该网络结构连XOR关联的分类都无法分开。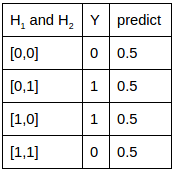
![([h_{1},h_{2}],y)](https://image.jiqizhixin.com/uploads/editor/53061899-b029-4646-a709-18aafe5881f8/1534141885878.png) 来拟合
来拟合 。其中每个数据可以用于确定2条关系线。
。其中每个数据可以用于确定2条关系线。 和
和 作为输入(用
作为输入(用 ,
, 表示),不考虑
表示),不考虑 。并且在网络结构中加入一个拥有2个节点(node)隐藏层(用
。并且在网络结构中加入一个拥有2个节点(node)隐藏层(用 和
和 表示)。
表示)。
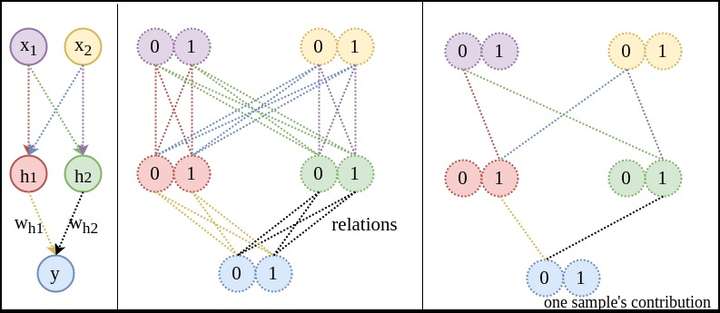
 和
和 的学习完全是独立并行。这就是神经网络的
的学习完全是独立并行。这就是神经网络的 和
和 的关联。也是Bengio大神所指的distributed representation。
的关联。也是Bengio大神所指的distributed representation。 就没有并行一说,因为
就没有并行一说,因为 是一个节点拥有两个变体,而不是两个独立的因素。但是也可以把
是一个节点拥有两个变体,而不是两个独立的因素。但是也可以把 拆开表示为one-hot-vector。这就是为什么分类时并非用一维向量表示状态。更验证了YJango在
拆开表示为one-hot-vector。这就是为什么分类时并非用一维向量表示状态。更验证了YJango在 的同时,
的同时, 和
和 也可以被学习。这就是神经网络的
也可以被学习。这就是神经网络的 和
和 :期初若用两条网络连接表示
:期初若用两条网络连接表示 的16个关系可能,那么熵会很高。但用两条线表示
的16个关系可能,那么熵会很高。但用两条线表示 的8个关系,模型的熵可以降到很低。下图中
的8个关系,模型的熵可以降到很低。下图中 的输出值对应红色数字。
的输出值对应红色数字。 对应输出值是由蓝色数字表达。
对应输出值是由蓝色数字表达。 :这时再看
:这时再看 的关系,完全就是线性的。光靠观察就能得出
的关系,完全就是线性的。光靠观察就能得出 的一个表达。
的一个表达。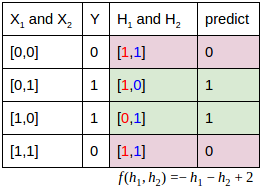
 与用一条
与用一条 所要拟合的关系数量有关。也就是说,
所要拟合的关系数量有关。也就是说, 有4个变体,这次把节点增加到4。
有4个变体,这次把节点增加到4。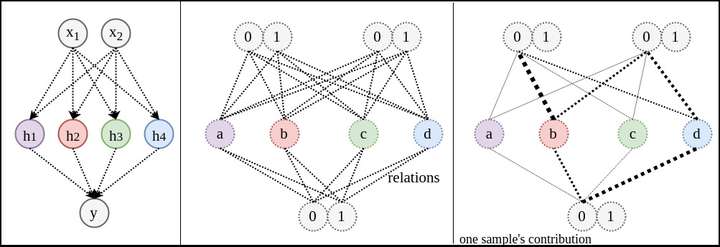
 和
和 的节点在滥竽充数。这就跟只有两个节点时没有太大别。原因是神经网络的权重的初始化是随机的,数据的输入顺序也是随机的。这些随机性使得权重更新的方向无法确定。
的节点在滥竽充数。这就跟只有两个节点时没有太大别。原因是神经网络的权重的初始化是随机的,数据的输入顺序也是随机的。这些随机性使得权重更新的方向无法确定。 ,
, 是惩罚的强弱,可以调节。除以2是为了求导方便(与后边的平方抵消)。
是惩罚的强弱,可以调节。除以2是为了求导方便(与后边的平方抵消)。 都有值。以这样的方式来使每个节点都工作,从而消除变体,可以缓解过拟合(overfitting)。
都有值。以这样的方式来使每个节点都工作,从而消除变体,可以缓解过拟合(overfitting)。 个节点。
个节点。 个隐藏节点。而代价也是需要
个隐藏节点。而代价也是需要 个不同数据才可以完美拟合。
个不同数据才可以完美拟合。

 ,
, ,比较不出来。下面YJango就换一个例子,并比较深层神经网络和浅层神经网络的区别。
,比较不出来。下面YJango就换一个例子,并比较深层神经网络和浅层神经网络的区别。 有8个可能状态,空间
有8个可能状态,空间 有2个可能状态:
有2个可能状态:

 只能用于学习一个节点(如
只能用于学习一个节点(如 )前后的两条关系线。完美学习该关联需要所有8个变体。然而当变体数为
)前后的两条关系线。完美学习该关联需要所有8个变体。然而当变体数为 时,我们不可能获得
时,我们不可能获得 个不同变体的数据,也失去了学习的意义。毕竟我们是要预测没见过的数据。所以与其说这是学习,不如说这是强行记忆。好比一个学生做了100册练习题,做过的题会解,遇到新题仍然不会。他不是学会了做题,而是记住了怎么特定的题。
个不同变体的数据,也失去了学习的意义。毕竟我们是要预测没见过的数据。所以与其说这是学习,不如说这是强行记忆。好比一个学生做了100册练习题,做过的题会解,遇到新题仍然不会。他不是学会了做题,而是记住了怎么特定的题。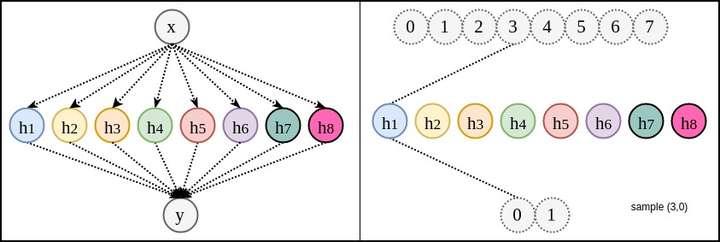
 训练数据。但不同
训练数据。但不同 之间有共用部分。比如说,在确定3和0关系时,也同时对所有共用
之间有共用部分。比如说,在确定3和0关系时,也同时对所有共用 连接的其他变体进行确定。这样就使得原本需要8个不同数据才能训练好的关联变成只需要3,4不同数据个就可以训练好。(下图关系线的粗细并非表示权重绝对值,而是共用度)
连接的其他变体进行确定。这样就使得原本需要8个不同数据才能训练好的关联变成只需要3,4不同数据个就可以训练好。(下图关系线的粗细并非表示权重绝对值,而是共用度)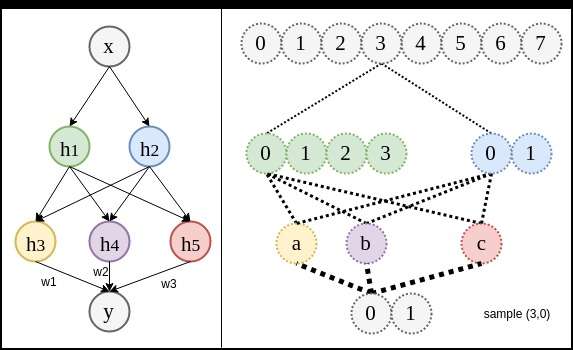
 解
解 ,需要2个不同数据。而深层神经网络好比用
,需要2个不同数据。而深层神经网络好比用 解
解 ,只需要一个数据。
,只需要一个数据。 去解实际上有
去解实际上有 的
的 ,或者去解实际为
,或者去解实际为 的关联时,搜索效果只会更差。所以深层的前提是:
的关联时,搜索效果只会更差。所以深层的前提是: 空间中的元素可以由
空间中的元素可以由 迭代发展而来的。换句话说
迭代发展而来的。换句话说 中的所有变体,都有共用根源
中的所有变体,都有共用根源 (root)。
(root)。

没有评论:
发表评论