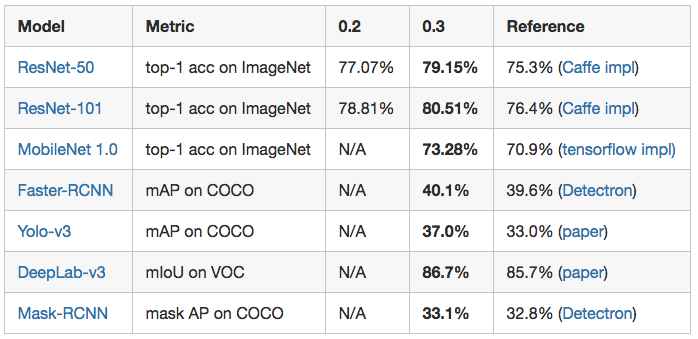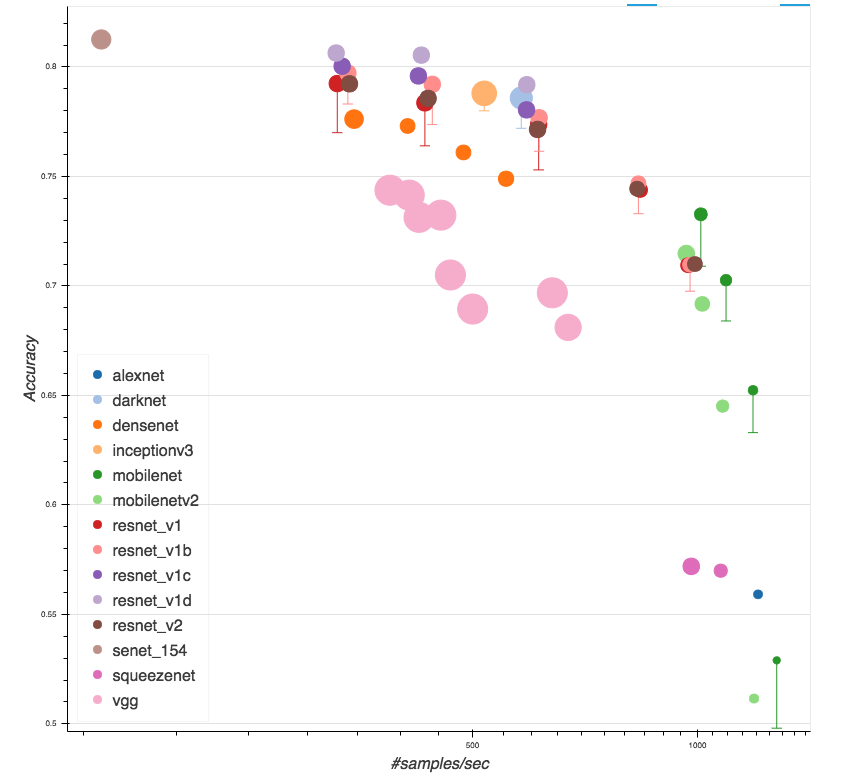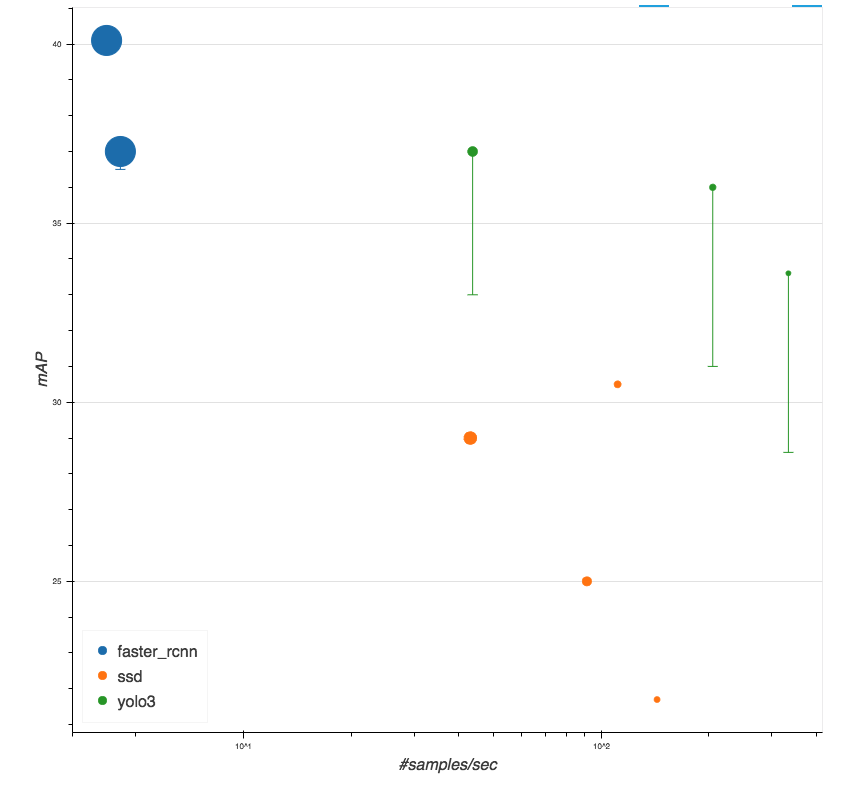
行为识别/视频分类 是视频理解领域的重要方向。之前该方向的深度学习方法大致可以分为两个大类:一类是双流网络,即以rgb图像和光流图像作为2D网络两个分支的输入,再在网络的某处进行融合,典型的如TSN;另一类则是将多帧RGB图像看做是3D输入,然后使用3D卷积网络进行处理,典型的如C3D,I3D,ARTNet等(当然也可以将光流作为3D网络的输入从而进一步提高效果的)。双流类方法的问题主要在于要提取光流,耗时比较多,在实际的场景中很难应用起来。所以近两年的论文更多集中在3D网络的研究上,3D类方法此前的问题主要有两方面,一是3D卷积核的计算开销比较大,二是在效果上还是距离双流类方法还是有一定的距离。
ECCV-2018上,新加坡国立大学,FAIR 和 360AI 实验室合作发表了"Multi-Fiber Networks for Video Recognition"[1], 代码见PyTorch-MFNet. 这篇论文主要针对3D网络的第一个问题进行了研究,具体而言,这篇论文的目的是要在保持网络效果的同时(主要对标I3D-RGBmodel),大幅度降低网络的FLOPs,从而提高网络的效率,使3D网络能够获得更多的应用场景。这篇文章提出的网络结构有点像不带channel shuffle 模块的ShuffleNet,其核心思想还是利用Group Conv来降低网络的计算开销。之前似乎没啥参考 mobile类模型思路来做video classification的工作,而计算量对于3D类网络又是比较重要的核心的瓶颈,所以这篇工作还是很有参考价值的。下面开始介绍文章内容,如有不足烦请指正。
Motivation
这篇文章的核心motivation就是认为目前的sota的3D网络(比如I3D以及R(2+1)D-34网络)的计算量FLOPs都太高了。常用的2D 卷积网络如resnet-152或是vgg-16网络大概是10+ 的GFLOPs,而刚刚提到的两种3D卷积网络则达到了100+ GFLOPs。作者认为,当计算量相近的时候,由于3D网络模型能额外的学习到时空信息,clip-based 的模型(即指3D网络)应该要能比frame-based的模型(即指2D网络)有更好的效果。所以,这篇文章的目标就是在保持现有sota的3D模型的效果的同时,大大提高其网络效率。
多纤维网络
在方法部分,作者首先介绍了多纤维模块(Multi-Fiber Unit)的原理,然后在2D网络上实验了多纤维结构的有效性,最后将其推广到了3D网络上去。
多纤维模块
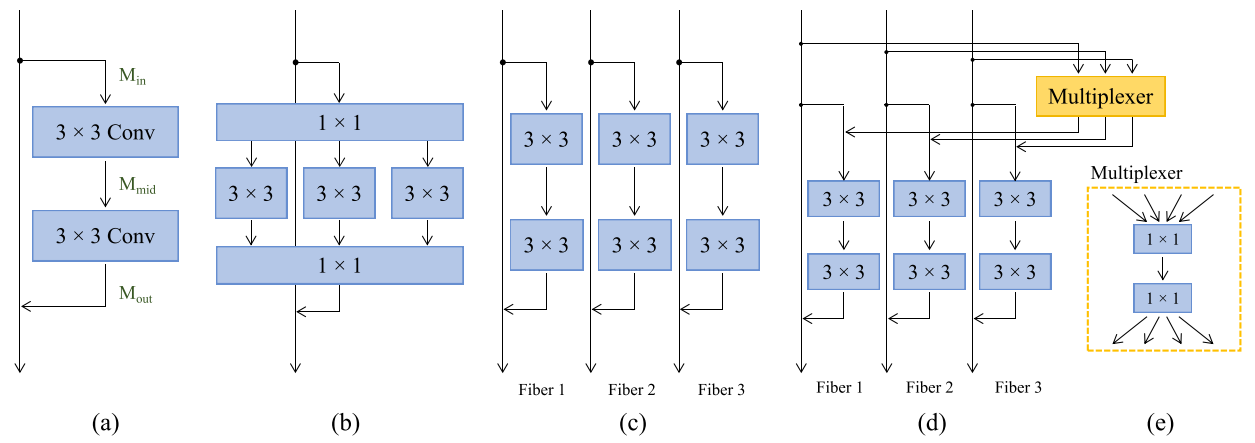
这张图介绍了从resnet到多纤维模块的变化过程。(a) 中的结构即是一个简单的残差模块;(b) 中的则为Multi-Path类型的bottleneck模块,比如ResNeXt就采用了该结构。在该结构中,前后均为一个1x1的卷积进行降维和升维,中间则将通道进行分组,分别用几个3x3卷积核进行处理。这样的处理可以大大降低中间层的计算量,但是1x1卷积层依旧有很大的计算量。所以这篇文章提出进行更加彻底的分组,即将整个残差模块按照通道切片成多个平行且独立的分支(称为fiber,纤维),如(c)所示。c中的结构在输入和输出通道数量一致的情况下,可以将理论计算量降低到N分之一,此处N为分支或者说是纤维的数量。这种更加彻底分组的加速思路和去年的ShuffleNet其实也有些像,区别在于ShuffleNet中还提出了channel shuffle的模块,且在中间层采用了depth-wise conv。
如(c)所示的结构虽然效率提高了很多,但通道间缺乏信息交换,可能会损害效果。所以该文进一步提出了一个Multiplexer模块用来以残差连接的形式结合纤维之间的信息。该模块实际上是一个两层的1x1卷积,第一个卷积会将通道数量降低到k分之一,第二个卷积再升维,因此该模块的计算量是一层1x1卷积的k/2分之一。不过,在文章中好像没看到作者具体设置的k值。
多纤维结构有效性的验证
接下来,作者通过在ImageNet-1k数据集上的图片分类实验来验证所提出的多纤维结构的有效性。这里主要有两种形式,一是基于ResNet-18和MobileNet-v2的baseline,将其中的模块替换为多纤维模块(这里具体的实现细节不是很确定);二是重新设计了一个2D MF-Net,具体网络结构可以见论文。实验结果如下所示。
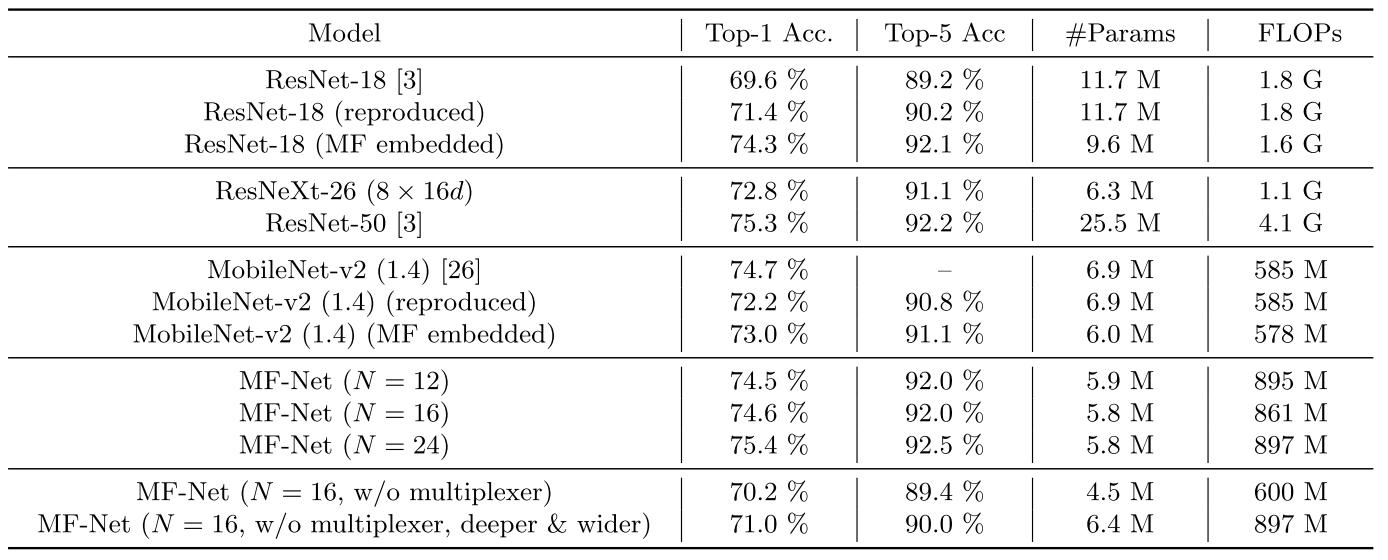
通过这个表格里面的实验结果可以看出。多纤维结构在MobileNet-v2和ResNet-18上可以在少量降低计算量和参数量的情况下,提高一定的效果,表明了多纤维模块的有效性。而MF-Net也在参数和计算量较低的情况下达到了不错的效果。最后一栏实验则表明了Multiplexer模块大概会占据30%的计算量,但对效果的提升也是比较明显的。
3D-多纤维网络
在确认了提出的多纤维模块的有效性后,本文就将多纤维结构推广到了3D网络上,并提出了3D MF-Net。3D MF-Net的模块结构和网络结构如下图所示:
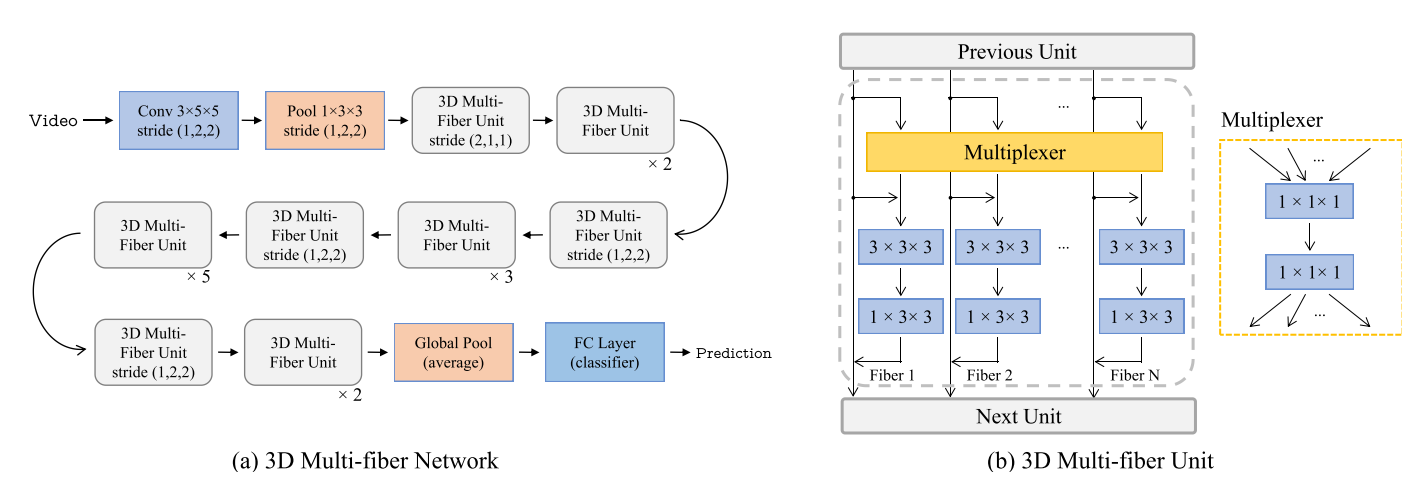
可以看出,3D和2D的多纤维模块结构基本一致,只是将卷积的维度升到了三维。为了降低计算量,两层卷积只有一层进行了时序上的卷积。
实验内容
在实验部分,本文主要做了trained from scratch以及fine tuned两类实验,分别对应Kinetics以及 UCF101,HMDB51数据集。
视频分类-Trained from Scratch
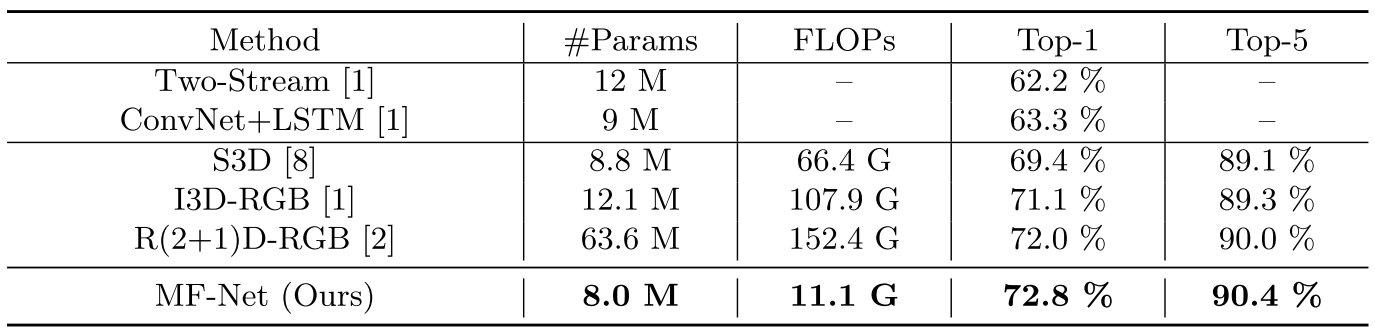
在Kinetics数据集上,MF-Net以比之前3D模型低非常多的FLOPs达到了更好的效果。
视频分类-Fine-tuned Models
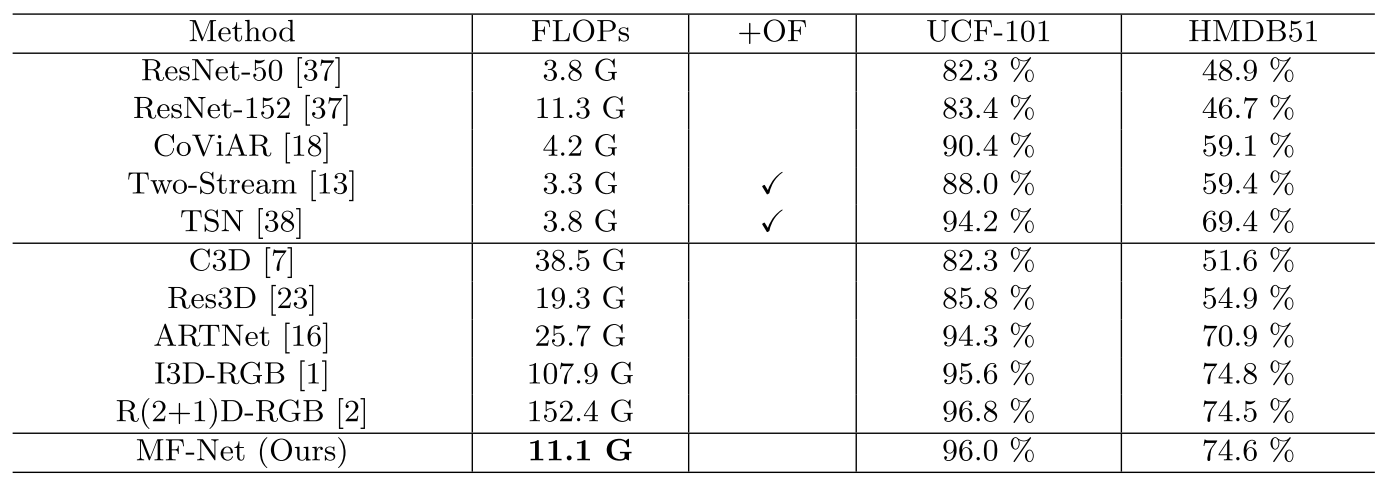
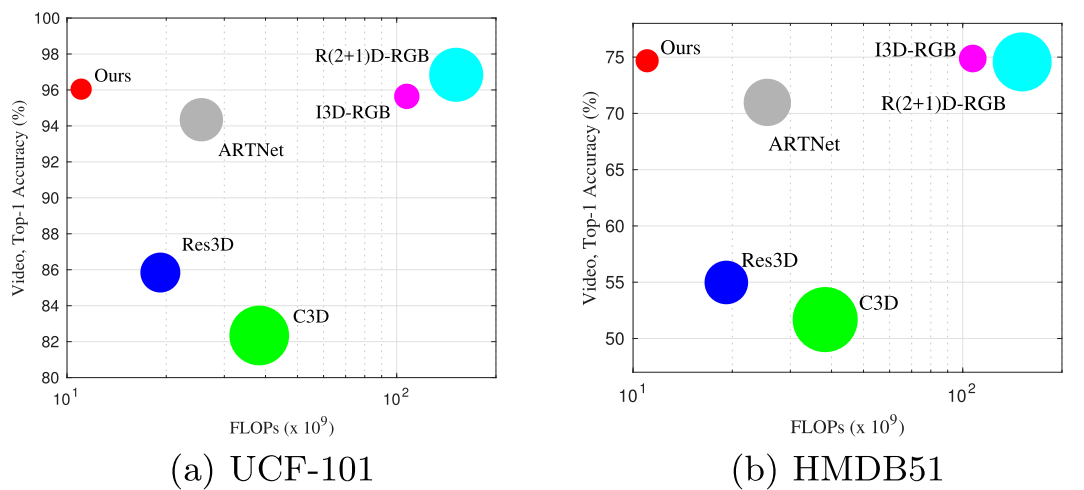
在这部分实验中,先将模型在大数据集(Kinetics)上训练,再在小数据集( UCF-101, HMDB51)上进行finetune。从实验结果可以看出,MF-Net以较小的计算量达到或超过了目前sota的效果。题图则更加可视化的展现了计算量和效果的关系图,可以看出MF-Net较好的占据了左上角的位置,即以较小的计算量达到sota的效果。
论文小结
这篇文章主要是进一步优化了Multi-Path模块的结构,并将其用于了3D卷积网络,从而大大提高3D卷积网络的效率。在效率大大提高后,其实也更有利于我们继续将网络做的更复杂更有效,像之前的I3D的效率实在太差了,很难进一步增加复杂度(当然另外一方面也给大家提供了很多优化空间和写论文空间...)。一方面通过引入网络加速技巧对模型速度进行优化,一方面通过增加网络对时序建模的能力来对模型效果进行提高 应该是未来3D网络研究更平衡的一种发展道路吧。
本文投稿于AI科技评论公众号, 未经许可请勿转载。
参考文献
[1]Chen Y, Kalantidis Y, Li J, et al. Multi-Fiber Networks for Video Recognition[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 352-367.
[2] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 5987-5995.
[3] Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 4724-4733.