
李林 李根 假装发自 阳谷(CA)量子位 出品 | 公众号 QbitAI
一想到众多美国公司流淌着中国血液,特朗普似乎就坐立难安。
从今年年初起至今,路透社、彭博社、《纽约时报》、《华尔街日报》等主流媒体一直在前赴后继地报道一件大事的进展:美国政府想要限制中国在美投资。
美国政府想出的限制方式不断花样翻新,但是大方针始终没有变:一切都是为了阻击中国在芯片、5G、人工智能、机器人等前沿技术领域的崛起。

目前最新情况是,美国参议院和众议院已经分别通过新法规,赋予美国外国投资委员会(Committee on Foreign Investment in the United States, CFIUS)更高权力,让它基于国家安全风险审查各类交易,其中包括外国资本对美国企业的股权投资、合资企业的建立,以及军事基地附近的地产交易等等。
美国政府还会在接下来几周里讨论、出台最终版本的法规。
今天,美国还开始了对出口管制政策的审查,想让这种管制和对外国资本在美投资的限制保持一一致,共同加强对美国国家安全的保护。目的,就在于不让中国等国家获得美国的"敏感技术"。
量子位询问了一些中国背景的硅谷VC朋友,他们目前情绪稳定。认为在中美贸易战背景下,美国政府对有中国政府背景的基金的审查是不可避免的趋势。
同时也表示,国内上市公司出海设立的基金不会受影响:硅谷VC不仅有丹华资本等政府资金作为LP的基金,也有越来越多的国内上市公司、个人LP支持的早期基金,比如Centregold Capital(南方中金环境股份有限公司在硅谷设立的美元基金,专注于投资环保、生物医疗类项目)等,这类基金不会受相关政策影响。
但是,美国的创业公司和它们的早期投资人有些坐不住了。
这不是断粮吗?
惊惶硅谷
据路透社报道,有消息称美国大牌风投基金Andreessen Horowitz针对创业公司发出了提醒:如果这些公司有中国背景投资者,就有遭到政府审查的可能。
对于硅谷创业公司而言,这显然不是个好消息。来自中国的资本进入愈加困难,拿了中资背景的钱,还要面临被美国政府审查的风险。
人工智能公司Skymind就是一例。

Skymind开发了Deeplearning4j深度学习平台和SKIL深度学习系统,来自中国的投资方有腾讯和香港曼图资本。
在业务运营上,这家公司和中国的联系也非常紧密。
比如去年12月,Skymind与福建省数字福建云计算运营有限公司达成合作,共同建设、运营"福建人工智能(AI)公共服务平台";
今年6月中旬,Skymind又和华为联手,面向行业应用,发布了华为硬件+Skymind软件的人工智能服务器。

阿里、中国联通等中国公司,也都在Skymind的客户之列。这家创始团队几乎没有中国脸孔的公司,面向中国的"技术出口"不可谓不多。
作为从中国融资的硅谷前辈,Skymind联合创始人、CEO Chris Nicholson对与这条融资之路已经不再看好。他对路透社说:"一些初创公司从中国获得融资的窗口可能正在关闭。"
研究公司荣鼎咨询(Rhodium Group)追踪的数据显示,中国对美国的投资金额正在逐年下降。2016年,中国在美国投资了大约450亿美元(约合2830亿元人民币),而2017年下滑到290亿美元,今年前5个月更是锐减到只有18亿美元。
对美国创业公司来说更严重的是,美国政府针对的,还不仅仅是中国资本。特朗普周二曾在白宫接受采访时说:"这种做法将针对所有国家。"
CFIUS的审查范围,包括所有可能向外国政府披露关键基础设施信息的投资。
掌握核心科技,就意味着以后可能只有本土资金可用。用这种方式与限制中国投资,大有杀敌八百自损一千之势。
对于美国政府限制向海外出口敏感技术的政策,《纽约时报》也曾有过类似评论:这对美国公司的影响可能比限制中国投资更大,因为它会限制美国公司向中国销售一系列产品的能力。
来自中国的诚意
让美国政府反复纠结的中国资本,究竟有多大规模?
风投数据公司CB Insights发布过一组数据:
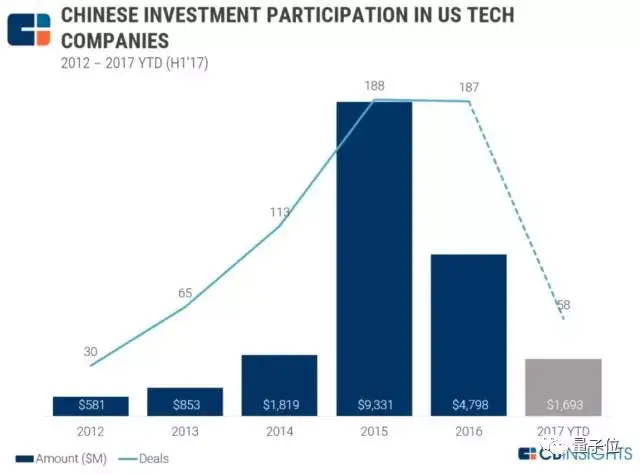
2012至2015年间,中国投资者向美国开展的科技投资交易增长超过5倍。这一趋势在2015至2016年间趋平。中国2017年的投资交易将出现38%的同比下滑。
2016年和2017年以来,中国投资者参与的美国科技交易只有不到一半处于早期阶段(种子轮、天使轮和A轮)。与此同时,2017年上半年,中国投资者参与的美国科技交易有19%属于B轮。
过去5年,人工智能的确成为中国投资者在美国的投资重点:自从2013年以来,中国投资者参与了美国人工智能公司的41笔交易。
但CB Insights的报告中,投资美国AI公司最活跃的是腾讯、创新工场等这样的产业及市场化VC。
然而即便如此,一想到中国资本正在抢夺美国高科技初创公司,特朗普可能真的睡不好觉——这些资本的LP构成说法,本质上可能只是说辞而已。
早在去年6月,美国方面便开始传出风声:将加强关于中国公司在硅谷投资的审查,以更好地保护被认为对美国国家安全至关重要的敏感技术。
这在当时不仅引发资本方面的担忧,而且也引来不少硅谷初创公司的呵呵。
一方面是加州民主自由的传统,另一方面则是中国资本的诚意。
比起老成持重的美国VC,中国VC显得更富"攻击性":愿意给更高的估值,决策速度更快,也更愿意承担风险。
由于国内优质AI项目估值越涨越高,不少国内VC开始面向硅谷砸钱,然后发现硅谷项目不仅质量高,估值还比国内便宜,一下子如获至宝。
李开复就感叹,如果要排序的话,国内AI项目估值>硅谷>加拿大。
而且在一些相似项目上,国内甚至是硅谷的2倍甚至更高,而这还是硅谷项目开始遭遇中国资本哄抢之后。
所以如果你是一家base硅谷的创业项目,同样拿钱发展,你是愿意拿美国土著VC的TS——100万美元占股20%?还是中国背景VC的TS——200万美元占股20%,而且还有投后服务帮你开拓中国市场。
创业的本质就是生意,真金白银的认可就是最大诚意。
然而现在,商人出身的特朗普说:创业有国界,拿投资可以不讲新钱旧钱,但得讲政治。

所以也有硅谷VC告诉量子位,为了生意不受限制,也有越来越多的硅谷华人背景的基金不仅从国内募资,同时也在寻求美国本土、欧洲、东南亚等地区的LP支持,并且进展顺利,这类基金不会受政策影响。
当然,特朗普执政的这2年,资本方面的限制只是一方面,还有更多看不见的"小动作"。
比如中国科技创业者前往美国参加国际学术顶会,限制就在明显增加。
单就今年CVPR,不少国内优秀AI公司的赴美签证就遭到大规模check,而且给这些中国AI人才都是一年一签——意味着明年签注可能还要被check,类似的做法,历史罕见。
撕裂美国政府

其实,如何限制中国在美国的投资,以及美国公司向中国出口"关键"技术,在美国政府内部经历了一场漫长的拉锯战。
在近期曝光的各种方案之中,通过CFIUS来审查交易已经算是相对温和的结果。
今年3月,美国财政部的强硬派为了限制中国资本赴美投资,曾考虑动用1977年出台的《国际紧急状态经济权力法》。这份法案曾经用来对伊朗和苏丹实施经济制裁。它将庞大的权力赋予总统,如果真的启用,特朗普就能阻止交易进行、取消交易、冻结外国资产。
以财政部长努钦(Steven Mnuchin)为代表的温和派则一直担心,这种强硬的措施可能会抑制经济发展,扰乱金融市场。
漫长的拉锯战之后,目前看来,似乎是温和派胜出了。
One More Thing
特朗普为美国2020大选的宣传活动已经开始了。这周在威斯康星州的演讲中,特朗普表示,将面向支持者们推出新的应援周边:
绿帽子。
上一轮大选中总戴着红色帽子的特朗普说,会把新的竞选口号"Keep America Great!"印在绿色帽子上,因为绿色代表钞票(美元)。

— 完 —欢迎大家关注我们的专栏:量子位 - 知乎专栏诚挚招聘量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。量子位 QbitAI · 头条号签约作者վ'ᴗ' ի 追踪AI技术和产品新动态












