李根 夏乙 发自 凹非寺 量子位 报道 | 公众号 QbitAI
财报业绩好,Robin乐呵呵。
今日上午,百度交出2018年第二季度财报,超出此前华尔街最乐观的预期。
结合这份财报,以及李彦宏刚刚在电话会议上的发言,我们发现了百度业务的现状和未来前(钱)景几个亮点:
- AI开始在百度营收中发挥明显作用
- 李彦宏首次披露Apollo的商业模式
- 百度为自动驾驶开发的ACU浮出水面
对于百度交出的这份答卷,资本市场当然不可能没有反应:财报发布后,百度股价盘后上扬,涨幅一度近5%。
AI开始赚大钱
首先,这是一份业绩为总营收人民币260亿元(约合39.3亿美元)、净利润人民币64亿元(约合9.67亿美元)的财报。
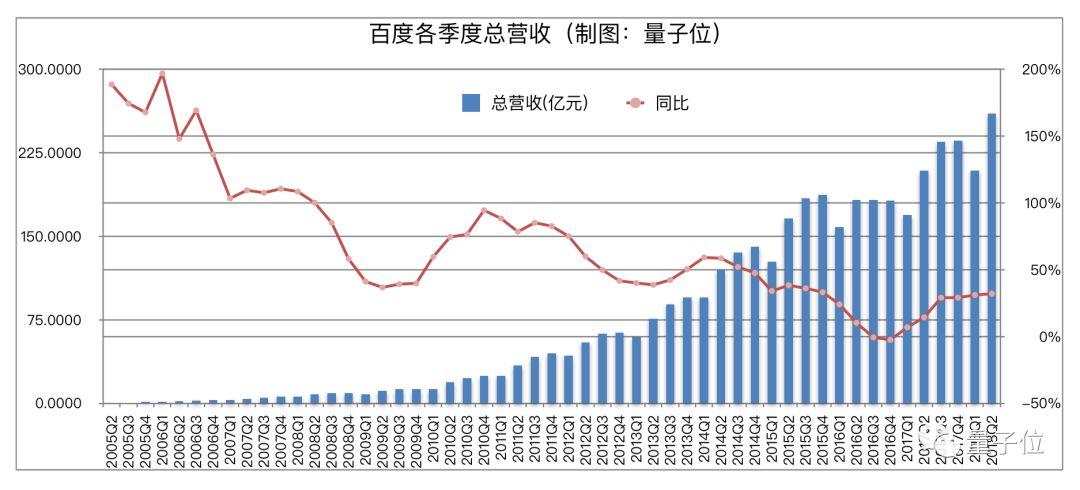
什么概念?
直观类比来说,一个季度赚的钱,超过了中国第二大搜索公司的总市值;一个季度所得利润,超过了个别老牌门户的最新市值。
如此一比,百度赚钱能力还是蛮吓人的。
那百度又是如何赚钱的呢?很简单,靠广告。
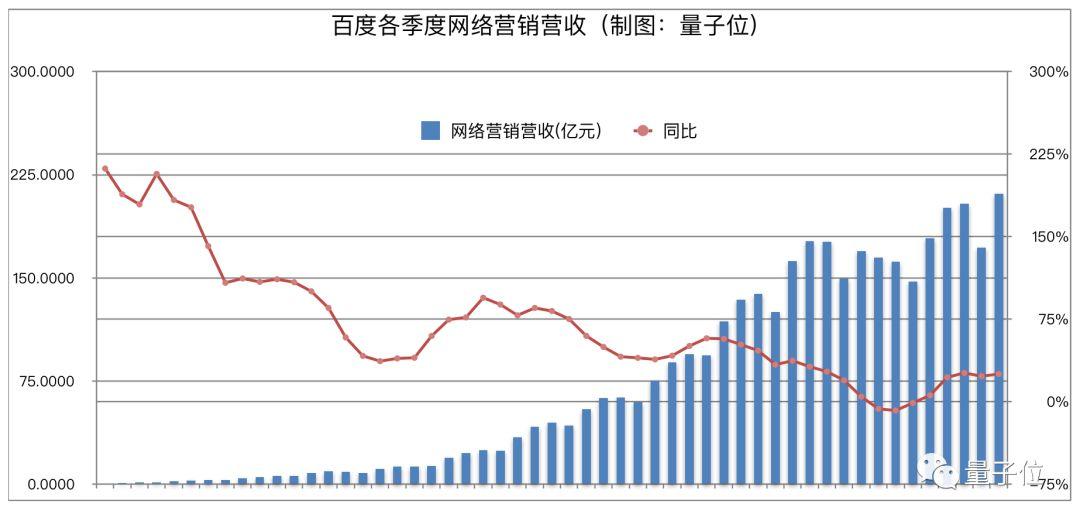
这一季度的百度营收,来自网络营销业务的有211亿元,同比增长25%。这个网络营销业务,约等于广告。
百度的广告,过去集中体现为搜索广告,现在的主力则是搜索+信息流,双引擎驱动。
广告业务这样的增速,得益于双引擎,也得益于技术的创新,特别是AI加持。李彦宏自己也说,中国互联网用户总量增速是在放缓的,接下来业务发展的主要驱动力是技术创新。
对于百度来说,主力自然是AI。
AI对广告业务最直接、最明显的助力,在于转化率的提升。
用户画像和推送都得精准,信息分发和广告匹配都得同时"在线",否则赚点钱OK,赚百度这么多钱不容易。
百度披露的是,自从用深度强化学习优化广告效果后,能为广告主提出更好的关键词、图片、视频建议,提升转化率和广告的接受度。
AI加持之下,用户体验的进步也会间接提振广告业务。
具体数据方面,搜索结果首条直接满足需求比例达37%,搜索结果中有38%来自熊掌号优质内容,同时超过1/6的搜索PV都覆盖高质量的视频结果。百度App的日活则达到了1.48亿。
当然,内容质量和广告内容也需要配合得好,不能太过伤害用户体验。
于是李彦宏也开诚布公表示:业绩强劲、搜索业务收入增长明显、信息流业务流量和商业化增长势头良好,背后就是AI驱动。
此外,商业营收增长势头凶猛,AI变现能力崭露头角,也算是给其他AI业务未来预期增强了信心。
在整个百度AI战略中,信息流是夯实的基础,也还是开路先锋。
过去一年百度战略梳理中,成熟变现的搜索+信息流,被列入核心,而更具中长期远景的业务则相应有所剥离,区分更加明确,利于市场和投资者认知,但整个中轴仍是AI。
其中,隐隐展现出最大潜力的是家居领域的DuerOS、车领域的Apollo,以及包含二者在内的整个AI开发者生态。
这3大方面,目前都进入了规模化落地序列,虽还不能直接变现,但未来预期已经放出来了。
李彦宏点明Apollo商业模式
自动驾驶领域的Apollo是上一季度最抢镜的业务。
在百度刚刚结束的AI开发者生态上,李彦宏宣布阿波龙实现第100辆量产车下线,首批还会在北京、雄安、深圳和日本东京商业化运营。

阿波龙是百度和金龙汽车合作的L4级完全无人驾驶小巴,是Apollo能力的代表作。
目前在全球范围内,正式量产商用L4级无人车,都是头一件,所以阿波龙第100辆量产车下线消息一宣布,制造方金龙汽车随即涨停。
除了阿波龙,在发布Apollo3.0版本后,百度还宣布在货运领域、限制场景无人驾驶领域都能更进一步,加快量产商用步伐。
在最新生态里,目前已有119家OEM合作伙伴,并且跟全球车企大厂奔驰-戴姆勒、宝马等达成合作。
所以你可能也好奇,开放了核心技术能力,又圈了这么多盟友的Apollo生态,未来到底如何变现?
嗯,这一次,李彦宏亲自透露了几个商业模式。
百度掌舵者说,无论是Apollo还是DuerOS,现在都处于早期积累阶段,未来几个季度都不会产生实质营收贡献。
但Apollo发展得好,变现并不是什么大挑战。
未来通过Apollo的生态,百度可以卖高精度地图、卖仿真平台、甚至卖计算硬件ACU,这些都是很直接很刚需的服务。
高精度地图和仿真平台,之前在Apollo1.5版本就有隆重介绍。
高精度地图是百度多年技术囤积所在,研发在2013年就已启动,采集车队规模近300辆,融合了实时地图构建及定位技术(SLAM)、深度学习、图像处理、计算几何等处理技术,建立了亿量级样本库,能够精细刻画道路上的交通标志、车道线、护栏路沿等上百种要素和属性,数据精度达到厘米级别。

更主要的是,百度高精度地图自动化处理程度超90%,准确率高达95%以上。依托多源感知数据处理、云服务中心和数据中心等构成的Intelligent Map平台,可以实现分钟级的更新。
而配合高精地图,百度的定位技术在城市高楼密集市中心、林荫路、隧道、地库等极具挑战的弱/无GPS场景下也可达到厘米级定位。
仿真平台则内置高精度地图,把海量中国国情的交通场景纳入其中,覆盖了诸多极端情况,帮助开发者优化真实场景下的应对方案,确保自动驾驶车辆上路安全。
同时,Apollo还对外称,仿真平台提供了贯穿自动驾驶研发迭代过程的完整解决方案,帮助开发者发现问题、解决问题和验证问题。
作为证明,百度推出Apollo仿真平台后,在两个月的时间内,跟智行者合作推出了一辆落地的无人驾驶扫地车。

李彦宏要卖的硬件,叫做ACU(Apollo Computing Unit)。今年1月,百度提到将来会销售一系列硬件,能够直接插到车上运行他们的软件,实现自动驾驶功能,这个硬件,就是今天提到的ACU了。
另外,还有一些软硬件一体的方案,比如现在畅谈甚广的代客泊车解决方案,Apollo生态里做出来很轻松。不管是L3,还是L4,Apollo都有广泛的变现机会。
最后还有看不见的红利。因为Apollo团结了诸多力量,进展也很迅速,于是百度得到了中国官方层面的创新支持,可以最早开始基础设施层面的合作,给出路面传感器方案的建议,这也意味着未来无人车不需要昂贵的激光雷达等传感器。
总之归结起来一句话,Apollo已经量产落地,虽然还不能直接贡献营收,但变现起来也机会不少。
(这些电话会议上的回答,也算先给了华尔街一个"交代"。)
DuerOS不急变现
另一项中长期"潜力股"是DuerOS。
数据上看进展也很神速。李彦宏在财报分析会议上专门夸赞了DuerOS,说小度智能音箱系列及相关产品倍受好评,2018年6月DuerOS语音唤醒超过4亿次,几乎是三个月前的两倍。
DuerOS的用户增长让厂长很开心,他表示即便还不到谈商业变现的时候,但业务进展如此之快,如果这个领域可以变现了,百度也会是头一家。

在第二季度里,财大气粗的百度推出了售价89元的智能音箱,把国内智能音箱的竞争拖入了百元大战,也带动了DuerOS系统快速进入更多寻常百姓家。
另外,百度还把DuerOS带给了20多家车厂,包含宝马、奔驰-戴姆勒、福特、现代、起亚、奇瑞、北汽和一汽在内的大车厂,都计划推出DuerOS提供的车载语音交互、人脸识别,AR等方面的功能。
Apollo和DuerOS,也在此形成了协同效应。
其他进展
最后,百度AI航母中最基础也最长远的项目,莫过于AI开发者生态。
百度在刚结束不久的AI开发者大会上推出了百度大脑3.0,并且提供了EasyDL,AutoDL和AI Studio等系列开发工具包,以此推动深度学习平台PaddlePaddle的应用。

而且在基础设施层面,昆仑芯片也已经宣布,云端和终端的AI开发者生态,百度都有落子。
隐而未宣的是,百度云也在后发情况下快速追了上来,目前跟阿里云和腾讯云一道,处于国内公有云第一梯队,To B和To G方面的AI商业项目,也已闷声展开。
不过AI开发者生态能展现的潜力和能力,或许需要更长的时间,但百度目前的优势也是显而易见的:百度披露数据称,刚结束的AI开发者大会有全球7300多人来到北京现场。
当然备受关注的,还有百度的智能小程序。
在分析师电话会议上,小程序是被提及最多的问题之一,但是目前似乎百度也没有更多实质性的进展可以对外披露。
等下一季财报再说吧。
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI· 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态