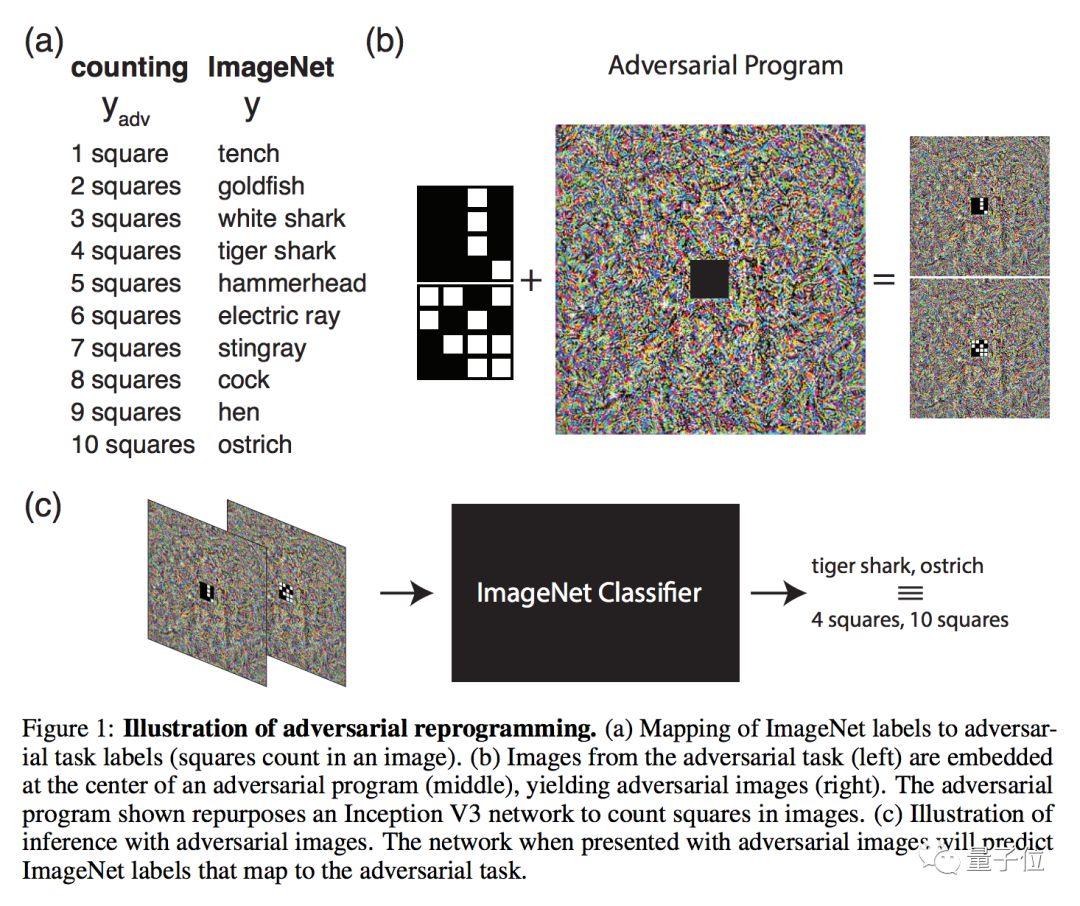
| 「它能实时识别数百万张人脸,并从海量照片中精准检测出多达 100 张。」 亚马逊这样描述自己的人脸识别软件 Rekognition Technology。
但是几个月之后,它就卷入了美国警方监控纠纷。 美国人权联盟披露的文件显示,亚马逊把这个强大的人脸识别软件授权给了佛罗里达州奥兰多市和俄勒冈州华盛顿县的警方,让他们来监控人群。
以奥兰多市为例,软件能够实时追踪和分析全市几个摄像头的监控数据。另外,Rekognition 的推销内容中还特别提到,监控系统能连上警方的随身摄像头。 文件披露后,奥兰多市的警察局局长 John Mina 试图缓解公众的担心,他强调:
「我们永远不会把这项技术用于追踪普通市民,移民,社会活动者或者有色人种,」Mina 在一次记者招待会上保证。 「这是个实验项目,我们只是在测试这项技术是不是管用。」 然而,全世界都开始担心这种监控技术的滥用了。
人工智能和监控的结合在实际应用层面和道德层面都会带来问题,这引发了高层对这些带有原罪的科技公司的警惕。 与此同时,民间的反击战也打响了。
就像法国著名哲学家 Paul Virilio 说的那样:有了船只,就会有海难。有了灯塔,就会有海盗。 人脸识别软件的人种偏差 现实表明,人脸识别的有效性并不够。
位于英国的人权组织 Big Brother Watch 的一份报告发现,伦敦市警察局的人脸识别配对结果有 98% 的错误率。
南威尔士警方在演唱会、节日庆典和皇家访问等场合的相似试验在 91%的时间里都识别错了人。 考虑到白人的人脸识别结果误差要小很多,这种失准又多了一层含义。
根据纽约时报的报道,微软,IBM 和 Face++ 联合进行的算法研究发现,浅肤色男性的性别识别错误率只有 1%,浅肤色女性为 7%,而深肤色男性的到了 12%,深肤色女性的甚至高达 35%。 「虽然很敏感,但是从根本上说,当我们讨论人脸识别的时候,我们在解决身份政治,」一家国际有色女性技术专家联合组织 Hyphen-Lab 通过邮件告诉我们。 新兴技术「中立」的假设,掩盖了它们会放大潜在的人种和性别误差的事实。这创造了一种加大歧视的机器,随身摄像头从可信赖的工具转变成了看不见的监控引擎。 对于 Hyphen-Lab 来说,有一些事情需要被测试,询问,以及颠覆。 「公众隐私权真的需要拓展到有色人种社区,」这家组织说道。 「除此之外,对身份和形象的控制已经成了一种对那些历史上被集体边缘化的人群进行自由压迫的方式,无论是美国还是全球其他国家。」 「我们想要掌控自己的身份,命运和形象。」 Hyphen-lab 开展了一个由 Ece Tankal,Ashley Baccus Clark 和 Carmen Aguilar Wedge 领导的项目。
该项目展示了在一个实时识别和追踪人脸的社会里,如何反击监控。 一个 HyperFace 面具原型,它可以迷惑人脸识别软件。 艺术家兼研究者 Adam Harvey 和这个团队一起设计了并创造了一条扰乱计算机视觉算法的围巾,它的紫色的材料布满了奇怪斑点——一种 21 世纪的迷彩伪装,可以发送潜在配对以迷惑摄像头。 「如果我们对机器的输入了如指掌,我们就能欺骗,诱导和利用它们来解决我们过分依赖它们而产生的问题,」Hyphen-Lab 解释到。 这条围巾是 Hyphen-Lab 的更宏大的 NeuroSpeculative AfroFeminism 项目的一部分,这个项目还包括了内嵌摄像头的耳环和一个 Afrofuturist「神经美容术」沙龙,它们全都在探索黑人女性在科技行业的角色和形象。 当讨论到人脸识别的时候,这条围巾可以吸引人们的注意力,让大家注意到新型监控技术的不完美,基于缺陷算法搭建的机器很可能会被欺骗、规避和劫持。 如何扰乱一个计算机系统 Hyphen-Lab 承认这条围巾的实际效用还不明确,因为它是基于开源人脸识别软件的,算法更容易过时。
另外,这个项目是为了揭露隐私问题和政治监控。
「这让人生气,未经允许就利用我们周围的摄像头捕捉我们的一举一动,」这家组织解释到。 当 Hyphen-Lab 正尝扰乱交互时,其他人正尝试在技术层面扰乱人脸识别。 这种眼镜架能够欺骗脸部生物识别系统。 举个例子,来自卡耐基梅隆大学的研究员们开发了一种特制的镜架来扰乱计算机系统,这意味着穿戴者能够避免被认出,而且最让人印象深刻的是,甚至可以伪装成一个完全不同的人。
这次研究中,一个系统把一个人错认成了既是女演员 Milla Jovovich,也是男演员 John Malkovich。 在另一个斯坦福研究员 Jiajun Lu 领导的项目里,他创造了「对立示例」来欺骗图像识别工具,包括人脸认证系统和识别红绿灯以及交通情况的自动驾驶汽车系统。 对于前者,Lu 和他的团队创造了一个看起来很像 Google DeepDream 噩梦之一的伪装面具。
「通过使用我们的伪装,人脸在各种视觉条件下都不会被检测出来:角度,距离,灯光等等,」Lu 说。 一个 DeepDream 式的伪装面具,覆盖在一个人的脸部录像上。 然而,这项研究中的伪装是覆盖在一个人的脸部录像上的,Lu 告诉我们「制作纹身贴纸,放在一个人的脸上是小菜一碟。」 他建议试验「活纹身」,它由基因编程过的活细胞制作而成,可以用来达到试验目的。 这种活纹身的好处是,面具能够被设计成在特定条件下才会显现,纹身里的细胞被程序设计成只有在收到命令时才会显露它们的颜色,或者其他特定的环境条件被满足。
考虑到这个伪装面具会让你看起来像一个行走的致幻剂,它能够随你心意关闭是很有用的。 中国的监控技术实验平台 然而,Lu 并不是在为示威者,黑客或者间谍开发这些「对立示例」。他说,这项研究背后的想法是推动神经网络的设计者们去改进他们系统里的算法。 「深度学习领域里的人正变得对网络安全越来越担心,即使这些网络取得越来越多的成就。我们承受不住安全隐患。毫无疑问会有越来越多的人尝试攻击这些系统。」 把船打翻,缺陷会暴露出来,也就会有改进的地方。这提醒了我们,即使伦敦市警察局最近的试验结果不够准确,令人发笑,但是这项技术是在不断进化的。 如果你想得到下一个十年它会走向何方的线索,朝东边看。
虽然英国和美国在发展人脸识别系统上面临着技术上和政治上的全方位阻碍,在中国,则是另一番景象。 
商汤的监控系统在运行。 商汤科技,得益于公司的图像识别能力,这家处在中国 AI 热潮核心地位的公司的估值最近达到了 30 亿美元。
商汤的客户是一大堆政府相关的代理商,它们给公司提供了数量巨大的数据,这能让很多西方国家的 AI 公司垂涎三尺。
在与 Quartz 的对话中,商汤的 CEO 徐立指着一个超过 20 万张图片的训练数据库说到: 「如果你能拿到政府数据,你就有了全部中国人的数据。」 作为交换,商汤提供它的 Viper 监控系统,这个系统能把来自 CCTV,ATM 摄像头和办公室人脸扫描仪的影像资料收集起来,能够同时处理 10 万在线视频流数据。 在这些技术的核心地带,身份政治问题再次出现了。毕竟,在过去的几年里,这项高端监控技术的实验平台大多都放在边远省份,也是因一连串恐怖主义活动而备受指责的地方。 商汤强调 AI 图像识别可以用来做好事,比如可以用来帮助寻找丢失的小孩。这种看法在亚马逊的 Rekognition 系统上也有共鸣。 在美国人权联盟公开这家科技巨头与执法机关的合作关系细节之后,亚马逊发表了一份声明争辩到,Rekognition「在现实世界有很多用途,」包括在游乐园寻找丢失儿童。 毫无疑问这是事实,毫无疑问这也不是故事的全部。 图像识别的适用范围和能力在不断扩大,无论摄像头是在我们的手机里,在游乐场,还是在警察的胸部,我们的身份都是目标。 也许会有停止智能围巾和眼镜来欺骗系统的改进,但是一旦你发明船只,海南就会出现,海盗也会出现。 「我们知道会更新,」Hyphen-Lab 说。 「我们的手机,电脑,汽车都会更新,随着人脸识别技术的发展,我们仍然会坚持推出可能的手段来扰乱它的预期用途。」 ]]> 原文: https://ift.tt/2z5paYW |