| 0. 故事序言 如果有人问小夕:"小夕,要是人工智能的就业岗位一夜之间消失了,你会去转行做什么呢?" 答曰:"当然是去做Linux运维啊23333" 小夕有一台自己负责的GPU服务器,她可让小夕操碎了心呐,真是好不容易把这娇气的小公举拉扯大了。下面就向各位服务器宝宝的爸爸妈妈们传授一下育女经验,让她早日成长为一个省心的深度学习服务器。 下面小夕将依次介绍: - 操作系统建议
- ssh免密快速登录
- 内网穿透(跨网段访问服务器)
- 文件传输与实时同步
- 多开发环境管理
- 多任务管理(并行调参)
- 睡觉调参模式(串行调参)
- 关于Jupyer Notebook
- 单任务霸占GPU模式
- 来自订阅号评论区的其他神操作
  1. 操作系统建议如果你主要用tensorflow来作为你的深度学习框架,那么小夕还是建议安装16.04服务器版。注意是服务器版!为什么呢?因为有很多显卡的高版本驱动与桌面版的图形界面不兼容,导致容易出现循环登陆问题,要解决循环登陆问题也是极其的麻烦,小夕曾经在所里配的笔记本上捣鼓过一周多,重装10余次系统,尝遍国内外各种方法,最终放弃╮(╯▽╰)╭ 所以这一次小夕直接为服务器装了ubuntu16.04的服务器版!注意服务器版是没有图形界面的,对shell不熟悉的童鞋要尽快打好基础哦。果然,在服务器版下装驱动装cuda一路next,0errors,0warnings  
由于小夕在高中时实在讨厌炸了国产软件全家桶对windows的狂轰滥炸,导致一遍遍的重复 while True: 系统变乱 系统变卡 重装系统
的过程,于是大学里在一学长的诱惑下,成功入了mac的坑,从此整个世界都清净了,同时对命令行(mac与linux都是基于posix标准,命令行/shell语法高度相似)的沦陷一发不可收拾。。。(好像又跑题了?咳咳,小夕是想说,由于最近几年很少接触windows了,所以本文所列tricks可能对windows的兼容性略差。不过话说回来,做深度学习的日常怎么可能在windows上进行啊喂,不知道pytorch都懒得出windows版本了嘛。(放钩--->
2. ssh免密快速登录远程登录最最方便的当然就是ssh啦。看小夕的一键登录! 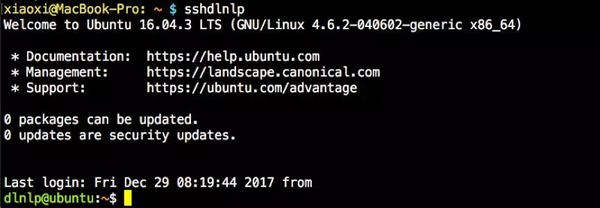 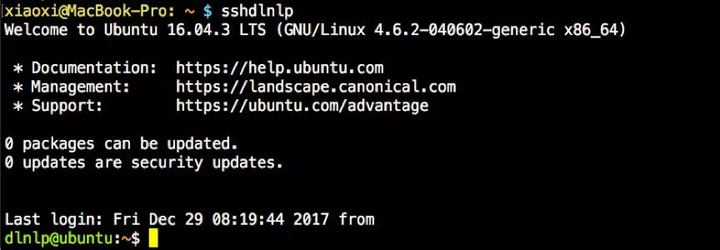 第一行黄色的是小夕的用户名、电脑名、当前目录。小夕设置的命令就是sshdlnlp,敲上这个命令直接进入服务器! 实现这个非常简单,分两步: 首先,将你的登录命令写入你的pc端的bash启动脚本中。Mac系统为 ~/.bash_profile ,linux系统为 ~/.bashrc 。例如你的服务器用户名为dlnlp,ip为102.10.60.23,那么就把这句登录命令写进去: alias sshdlnlp="ssh dlnlp@102.10.60.23"
感谢评论区 @karajan1001 指出,还有一种更科学强大的方法:将你的服务器信息写入PC端的ssh配置文件中,配置文件位于 ~/.ssh/config ,例如你的服务器用户名为dlnlp,ip为102.10.60.23,那么就把这句写进去:
Host dlnlp
[一个Tab]User dlnlp
[一个Tab]Hostname 102.10.60.23
[一个Tab]Port 22
(Host后面那个dlnlp是你起的名字,你也可以用更简短的名字)
这样可以 ssh dlnlp 也能快捷登录,注意中间的空格哈。而且scp也更加方便了。 当然,登录命令叫sshdlnlp,你也可以改成别的。保存后别忘 source ~/.bash_profile 或者 source ~/.bashrc 激活一下启动脚本哦。 然后,经过第一步后,只需要再敲密码就可以进入啦。但是懒癌至深的我们怎么能容忍敲密码这么麻烦的事情呢!(划掉,应该是小仙女怎么能容忍敲密码这种事情呢)但是我们又不能牺牲服务器的安全性,那怎么办呢?考验大学里计算机网络基础的时候到了~ 也很简单,把你PC端的ssh公钥写入服务器的ssh信任列表里就可以啦。首先用`ssh-keygen`命令生成rsa密钥对(生成一只私钥和一只公钥),一路enter即可,但是注意:   之前有已经生成过的同学在此处就选择n吧,没有生成过的同学就一路next~ 然后去 ~/.ssh/ 文件夹下将公钥发送到服务器上的某文件夹里:   然后去服务器上,把你PC端的公钥丢进ssh信任列表: cat id_rsa.pub >> ~/.ssh/authorized_keys
好啦~搞定啦,再回到你的PC端登录试试吧,是不是连输入密码都省掉啦。 3. 内网穿透(跨网段访问服务器) 但是注意哦,如果你的服务器是在局域网内,那你的PC离开这个局域网的时候当然就找不到你的服务器啦。想要在家里用GPU服务器?很简单,小夕教你分分钟内网穿透! 在内网穿透方面,小夕试了好几种方案后,感觉还是花生壳对新手最友好也最稳定。我们的内网穿透只需要将服务器内网ip以及22端口号(即ssh端口号)映射到外网ip的某个端口号。这个过程使用花生壳非常简单,在网上有很多教程,小夕就不啰嗦啦。之后我们要做的就是将这个外网ip和端口号也封装成一条命令,比如花生壳分配给我们的外网ip是103.44.145.240,端口是12560,那么只需要把这个写入客户端shell启动脚本: alias sshdlnlp_remote="ssh -p 12560 dlnlp@103.44.145.240" (别忘用source刷新启动脚本)
之后就可以在世界各地用一条命令访问你的gpu服务器啦。 4. 文件传输与同步对于一次性的文件传输,这方面最简单的当然还是直接使用scp命令啦,文件夹和文件都能轻松传输。 但是我们做深度学习的话,在服务器端大面积改代码、重量级调试的话还是不方便,毕竟服务器上没有图形界面,大部分人还是用不惯vim的,那么能不能在PC端用漂亮的编辑器修改代码,将修改结果实时的同步到服务器端呢?当然可以!这里小夕推荐文件同步神器syncthing。 剩下的就是傻瓜式配置啦。记得要更改文件夹刷新频率哦(默认是60秒,我们可以改的短一点,比如3秒),这样在客户端我们用漂亮的文本编辑器对代码的改动就能实时的同步到服务器上啦,在服务器端就只需要负责运行就可以咯。 5. 多开发环境管理如果不幸你的GPU服务器并不是你一个人用,那么这时多人(尤其是混入小白多话)经常把服务器默认的python环境弄的乌烟瘴气,比如有人用python2,有人用python3,有人用tensorflow1.3,有人用0.12等...最后导致大家的程序全跑崩了。 所以在服务器端管理深度学习的开发环境是极其必要的,这里anaconda直接搞定!每个人建立和管理自己的开发环境,包括python版本、各种库的版本等,互不干扰。而且在发布project时,也方便直接将环境导出为requirements文件,免得自己去手写啦。 6. 多任务管理(并行调参)如果你的服务器上有多个GPU,或者你的任务消耗GPU资源不多,那么并行的训练模型调参数是极大提高开发效率的!这里小夕给出几种场景下的常用方案: 1、比如我们在服务器上除了训练还要接着干别的事情(比如还要捣鼓一下贪吃蛇什么的),那么我们就可以直接将训练任务挂后台。具体如下。 在linux中,在命令后面加上 & 符号可以将命令在后台执行,为了能看到训练日志,我们当时还需要输出重定向(否则会打印到屏幕上干扰正常工作的),所以比如我们调batchsize参数时可以这样: dlnlp@ubuntu:~$ python train.py --batchsize=16 > log_batch16.txt &
当然再挂上其他batchsize大小,如: dlnlp@ubuntu:~$ python train.py --batchsize=16 > log_batch16.txt & dlnlp@ubuntu:~$ python train.py --batchsize=64 > log_batch64.txt & dlnlp@ubuntu:~$ python train.py --batchsize=128 > log_batch128.txt &
通过 jobs 命令可以看到后台任务的运行状况(running、stopped等),通过 bg [任务号] 可以让后台stopped的命令继续running,通过 fg [任务号] 可以让后台的任务来前台执行。对于前台已经执行起来的任务,可以 ctrl+z 来丢进后台(丢后台时stop了的话用bg让其run起来)。 感谢微信用户A Bad Candy在微信订阅号后台留言提醒上面的丢后台方法会在ssh断开连接后进程终止,因此: 如果我们还不希望ssh断开后导致训练任务终止,那么需要再在命令前面加上 nohup 。如: dlnlp@ubuntu:~$ nohup python train.py --batchsize=16 > log_batch16.txt &
2、如果我们特别着急,不仅要并行挂着很多训练任务,而且都要实时的监控它们的训练进展,那么使用 screen命令吧,这个命令就相当于可以让你同时开很多个窗口(就像桌面上那样,你可以开很多应用程序的很多窗口),而且多个窗口之间可以轻松切换,同样这种方法不会因为ssh的断开而停止训练任务。 具体的操作可以直接在linux下 man screen 来查看screen命令的帮助文档。英文恐惧症的童鞋可以看本文参考文献[1]。 7. 睡觉调参模式(串行调参)大部分场合下我们没有那么多充裕的GPU可以用,我们一般只能一次挂一个任务,但是我们又有很重的调参任务,那怎么办呢? 依然很简单啦,首先,装好python-fire这个工具。 它可以非常轻松的将你的python程序变成命令行程序,并且可以轻松的将你要调的参数封装成命令行参数的形式。 然后,写一个调参shell脚本,把你要调的参数全都写进去!比如就像这样: 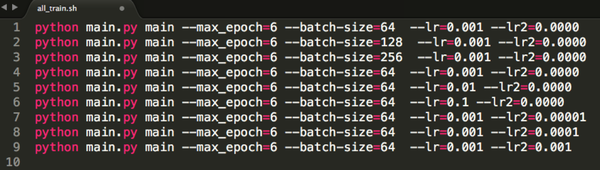 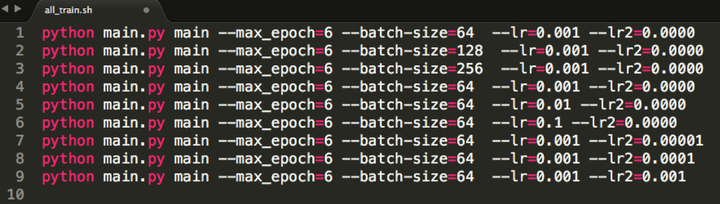 (当然别忘在代码里将训练的summary写到某个文件里) 然后就可以挂上这个脚本去睡觉啦~睡到天亮发现各个最优参数都找到了,超级开心有木有。 8. 关于jupyter notebookjupyter notebook这个神器小夕在历史文章中写过啦,也是一个重量级调参神器!或者直接可以说深度学习神器!在服务器端依然犀利的无可替代,只需要如下的tricks。 1、服务器端开启jupyter notebook后 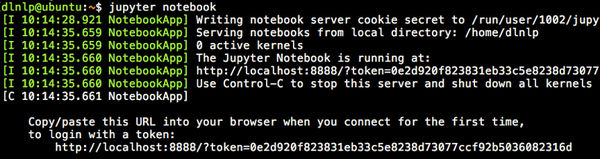 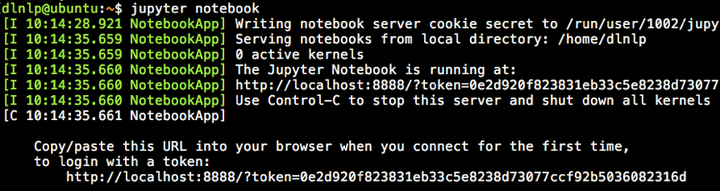 然后复制最后那一行的 token=xxx ,这个token就是远程访问的密码!同时记下 最后那行显示的端口号 8888(因为如果服务器上同时开多个的话,端口号就不一定是8888了哦),然后去PC端做一个端口映射!即通过ssh隧道来将服务器端的8888端口号映射到本地(PC端)的某个端口(如1234): ssh -L 1234:localhost:8888 dlnlp@102.10.60.23
(这个操作同样可以用于远程监视服务器端tensorboard) 这时就可以在PC端的浏览器 http://localhost:1234
直接访问服务器上的jupyter notebook啦~当然,访问时会让你输入密码,这时就输入之前记下的那个token哦。 2、让jupyer notebook跟anaconda开发环境融合。 默认的情况下jupyter notebook是运行在系统默认环境里的,如果要让它运行在我们自己用ananconda创建的环境中,要进入那个环境中,然后安装 nb_conda 这个库: conda install nb_conda
这时再开启jupyter notebook就能选择在我们这个环境里运行代码啦。 9. 单任务全霸占模式有时我们的训练任务非常重要且急迫,且绝对不允许被别人挤崩,或者我们明知要占用全部GPU资源了,那么这时我们就可以。。。emmm事先说明,非必要时刻请勿频繁使用哦: 使用linux中的 run-one 命令,这个命令可以保证同一条命令最多同时运行一个。比如 run-one python xxx 就会只允许运行一个python程序,后来的python程序在这个python程序执行完毕前是得不到执行的(一执行就会出错返回)。所以我们可以写入.bashrc: alias python='run-one python'
(别忘source激活哦) 这时 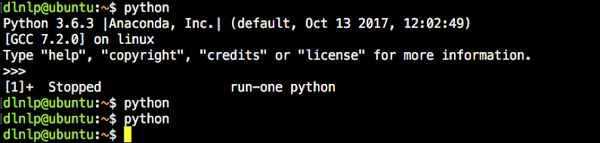 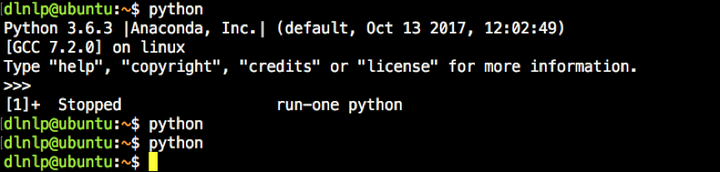 看,我通过将第一个python挂到后台了,后面的python完全执行不起来。除非前一个python结束。(所以其他小伙伴可能以为自己的程序出问题了,然后emmm陷入了无尽的困惑) 参考文献[1] 跑深度学习代码在linux服务器上的常用操作(ssh,screen,tensorboard,jupyter notebook) 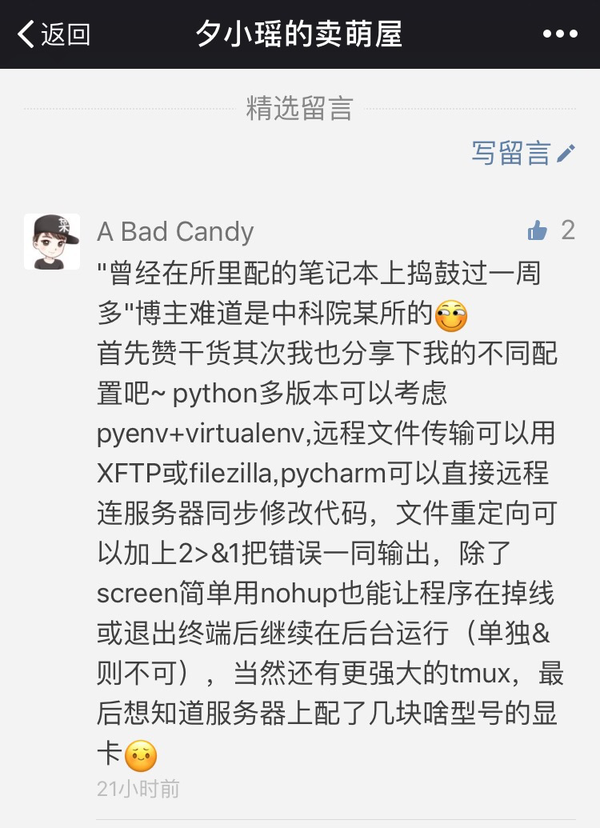  ]]> 原文: https://ift.tt/2IL6jSj ]]> 原文: https://ift.tt/2IL6jSj |