
水栗子 编译自 Medium 量子位 报道 | 公众号 QbitAI

感知,大概就是感受到周遭正在发生什么,的一种能力。这项技能对自动驾驶来说太重要了。
自动驾驶汽车依靠摄像头、激光雷达以及雷达等等传感器来感知周围的变化。
一位名叫凯尔 (Kyle Stewart-Frantz) 的大叔,准备了一份指南,鼓励大家在家训练自动驾驶系统的感知能力。

当然,这个手册并不是他出于爱好写出来的,是随着Lyft和Udacity联合发起的感知挑战赛 (Lyft Perception Challenge) ,而生的。
比赛考验的就是系统能不能准确地感受到,可以行驶的路面在哪里,周围的汽车在哪里。

挑战赛中,能够倚仗的所有数据,都来自车载的前向摄像头。
摄像头不存在?
这里的"摄像头数据"并非真实摄像头记录的影像,而是一个名为CARLA的模拟器生成的图景。
毕竟,自动驾驶汽车的软件开发大多是在模拟器中进行的,那里快速的原型设计和迭代,比在现实世界里使用真实硬件要高效得多。
那么,来看一下CARLA给的数据长什么样——

左边是模拟摄像头捕捉的画面,右边则是与之对应的、标记好的图像。
用这样的数据来训练算法,让AI能够在从未见过的新鲜图像里,判断出哪些像素对应的是道路,哪些部分对应的是其他车辆。
这就是挑战赛的目标。
车前盖太抢镜?
要完成比赛任务,自然会想到语义分割。用这种方式来训练神经网络,成熟后的AI便可以判断每个像素里包含的物体了。

第一步,是对标记好的图像做预处理。比如,因为设定是"车载前向摄像头"拍下的画面,每一幅图像都会出现车前盖,可是如果这样就把所有图像判定为"车",就不太好了。
所以要把显示车前盖的那些像素的值设为零,或者贴上其他的"非车"标签。
第二步,车道标识和道路的值是不一样的,但我们希望这些标识,可以被识别为路面的一部分。

所以,要把车道标识和路面,贴上一样的标签。
用Python写出来,预处理功能就长这样——
1 def preprocess_labels(label_image): 2 labels_new = np.zeros_like(label_image) 3 # Identify lane marking pixels (label is 6) 4 lane_marking_pixels = (label_image[:,:,0] == 6).nonzero() 5 # Set lane marking pixels to road (label is 7) 6 labels_new[lane_marking_pixels] = 7 7 8 # Identify all vehicle pixels 9 vehicle_pixels = (label_image[:,:,0] == 10).nonzero() 10 # Isolate vehicle pixels associated with the hood (y-position > 496) 11 hood_indices = (vehicle_pixels[0] >= 496).nonzero()[0] 12 hood_pixels = (vehicle_pixels[0][hood_indices], \ 13 vehicle_pixels[1][hood_indices]) 14 # Set hood pixel labels to 0 15 labels_new[hood_pixels] = 0 16 # Return the preprocessed label image 17 return labels_new
预处理过后的结果,就是标记和之前的不太一样了。
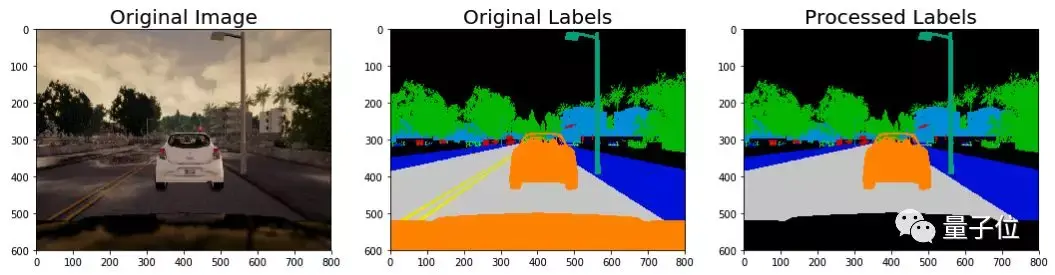
准备活动做好了,神经网络的正式训练也就可以开始了。
谁是分类小公主?
那么,大叔选的是怎样的神经网络?
定制一个FCN-Alexnet或许是个不错的选项,它擅长把每个像素分到不同的类别里。
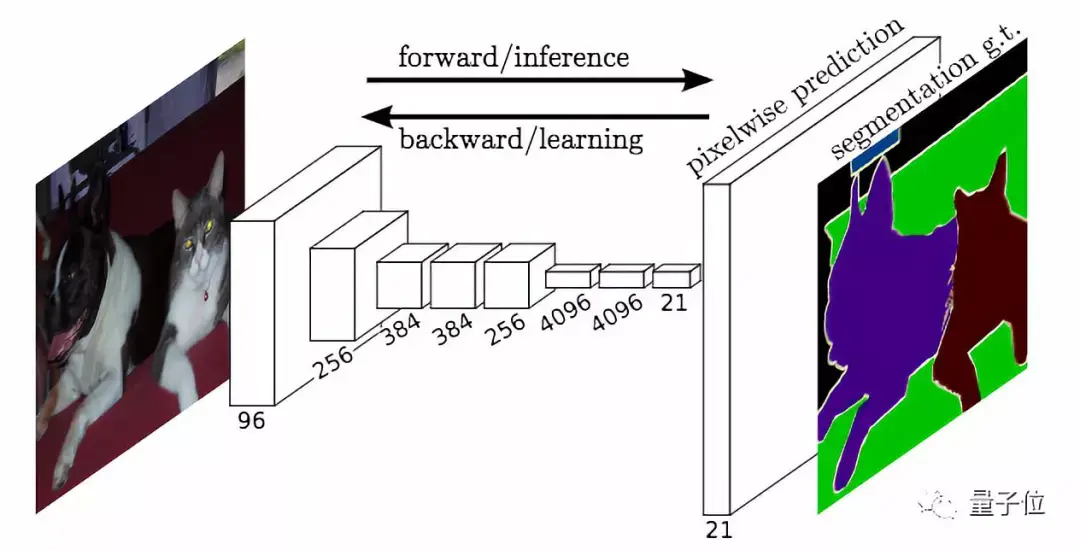
循着以下链接,可以找到这个模型的详细信息——
代码:https://github.com/shelhamer/fcn.berkeleyvision.org/tree/master/voc-fcn-alexnet论文:https://arxiv.org/pdf/1605.06211.pdf
大叔用一个随机梯度下降solver,把全部训练数据跑了10次 (10 epochs) ,基础学习率设的是0.0001。
评估训练成果
拿训练好的神经网络去跑验证数据,凯尔得到了0.6685的F2值,以及0.9574的F0.5值 (前者更重视召回率,后者更重视准确率) 。系统每秒处理6.06幅图像。
当然,视频会比这些数字更加生动——
然后还想怎样?
大叔说,要让神经网络表现更好,将来会搜集更多数据,涉及更加丰富的路况。
另外,要进行一系列的数据增强,让数据和数据之间的差异更加明显。
关于神经网络的结构,也还有其他选择,比如为细粒度预测而生的FCN-8,值得尝试。
还有,可以引入时态数据 (光流) ,来减少推断需要的帧数,同时保持比较高的准确度。
模拟器不够真?
当然,只有模拟器也是不够的,自动驾驶系统终究要接受现实的考验。
面对真实摄像头传出的画面,系统的辨识结果并没有非常理想。不过在许多帧里面,神经网络都能够在一定程度上,辨认出道路和车辆。
真实世界和模拟器里的驾驶场景,还是不一样的。
如果模拟器生成的图像和现实更加接近的话,可能结果就会好一些了。
不难看到,在和模拟器设定更为接近的路况下,系统的表现还是很不错的。
如此看来,这只AI还是很有前途。只要把模拟器造得更贴近真实,神经网络应该就能得到更有效的训练。
这里提供一段代码,可以用来查看,算法跑出的结果到底怎么样——
1 from moviepy.editor import VideoFileClip, ImageSequenceClip 2 import numpy as np 3 import scipy, argparse, sys, cv2, os 4 5 file = sys.argv[-1] 6 7 if file == 'demo.py': 8 print ("Error loading video") 9 quit 10 11 def your_pipeline(rgb_frame): 12 13 ## Your algorithm here to take rgb_frame and produce binary array outputs! 14 15 out = your_function(rgb_frame) 16 17 # Grab cars 18 car_binary_result = np.where(out==10,1,0).astype('uint8') 19 car_binary_result[496:,:] = 0 20 car_binary_result = car_binary_result * 255 21 22 # Grab road 23 road_lines = np.where((out==6),1,0).astype('uint8') 24 roads = np.where((out==7),1,0).astype('uint8') 25 road_binary_result = (road_lines | roads) * 255 26 27 overlay = np.zeros_like(rgb_frame) 28 overlay[:,:,0] = car_binary_result 29 overlay[:,:,1] = road_binary_result 30 31 final_frame = cv2.addWeighted(rgb_frame, 1, overlay, 0.3, 0, rgb_frame) 32 33 return final_frame 34 35 # Define pathname to save the output video 36 output = 'segmentation_output_test.mp4' 37 clip1 = VideoFileClip(file) 38 clip = clip1.fl_image(your_pipeline) 39 clip.write_videofile(output, audio=False)
用到的可视化数据在这里:https://s3-us-west-1.amazonaws.com/udacity-selfdrivingcar/Lyft_Challenge/videos/Videos.tar.gz
你也一起来吧?
当然,作为Lyft感知挑战赛的研发负责人,凯尔大叔这番苦口婆心的目的,还是吸引更多的小伙伴掺和进来。
道路安全,人人有责。大概就是这个意思,吧。

入门选手的各位,感受一下Udacity的免费课程:https://www.udacity.com/course/self-driving-car-engineer-nanodegree—nd013
注:有善良的中文字幕
以及语义分割的详细步骤:
https://medium.com/nanonets/how-to-do-image-segmentation-using-deep-learning-c673cc5862ef






