
Root 编译整理量子位 出品 | 公众号 QbitAI
霍金曾说过,通用人工智能(简称AGI)将会终结人类。

这类警惕AGI的言论,其实很久之前就有。
早在1951年,艾伦·图灵说过机器终会挣脱我们人类控制,接管这个世界。连工厂里使用大量机器人自动化生产特斯拉Model 3的马斯克,都反复公开强调,人类要积极监管,否则等回过神来的时候就已经来不及了。
澳洲国立大学三位AI学者Tom Everitt, Gary Lea, Marcus Hutter忧天下之忧,即将在IJCAI(国际人工智能联合会议)上发表一篇综述AGI Safety Literature Review,盘点了这几年全世界各地AI学者们对通用AI安全问题的思考。
简单了解一下AGI
如今我们生活中听过的或接触到的AI,只能处理单一问题,我们称之为弱人工智能。
单独下个棋,玩雅达利游戏,开个车,AI都hold得住。但现在的AI还没有"十"项全能的本领,无法同时做到在多个任务都表现得超过人类。

只有强人工智能,也就是AGI,才具备与人类同等的智慧,或超越人类的人工智能,能表现正常人类所具有的所有智能行为。
尽管现在并不存在AGI,但从人类把越来越多机械重复的工作都扔给AI解决这个趋势来看,AGI早晚会到来。
When?
曾有人在某年的NIPS和ICML大会上,组织过一场问卷调查。其中一个问题,请在场的顶尖学者们预测,比人类强大的AGI什么时候来。

调查结果显示,大家认为AGI会出现在2061年(结果取的中位数)。
掐指一算。也就还有43年。
AIXI模型,AGI学术圈内有望达到通用人工智能的模型之一,由本文作者之一Marcus Hutter教授于2000年首次提出。

他假设任何计算问题都可以转换为一个效用函数最大化的问题。
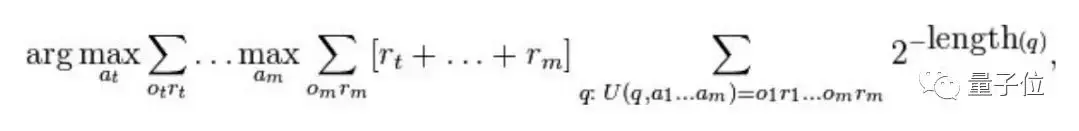
只用这一个公式,就概括出了智能的本质。
基于AIXI理论,Hutter教授和他的学生Shane Legg(也是DeepMind的联合创始人)在2007年对智能下了个定义:

agent的智能程度,是看agent在复杂的环境里完成任务的能力。
在大多数人的认知里,一旦两个agent同在一个环境里有着相斥的目标,那么智能程度更高的agent靠智商碾压对方来取胜。

这让很多人感到深深的恐惧。
如果哪一天我们成为了某个AGI目标的障碍物,那么比我们强大的AGI也很有可能会把我们清理掉。
围绕这层担忧,本文将从AGI可能造成的问题及人类的应对策略、公共政策这两个方面展开论述。
提前防范AGI宝宝造反
底层价值取向
第一个能想到的危险,是以AGI的智慧程度,它已经可以把目标分等级了。
比如说,算出π小数点后的第xx位数值,和追求提高人类的生活幸福指数相比,AGI可能会觉得前者很没意思。一旦AGI发展出自己的一套目标评价体系,那可能意味着它们不会乖乖"无脑"地完成人类交给他们的任务了。
所以我们人类一开始就要给AGI设计好底层的评价体系,相当于给它们一套我们人类做事的准则,一份moral code,价值取向。

现阶段,造AGI的最佳架构是强化学习。在单向任务上,棋类游戏、电脑游戏都用的强化学习。而采用强化学习的最大挑战在于,如何避免agent为了优化而不择手段抄近路。
不仅要防止agent篡改训练数据,维护好奖励函数的处理机制,还要小心最后输出的评估表现被扭曲。AGI想要做手脚的话,可下手的地方太多了。
因此,我们人类得充分想到每一种可能,做对应的防御机制。
稳定性
不过,即使辛辛苦苦教会它们怎么做一个好AGI之后,它们也有可能会在自我进化的过程中改写掉这些底层原则。所以设计一个稳定可靠的价值取向就很关键。
有学者Everitt, Filan认为,设计价值取向必须考虑的三大前提。
Everitt, Filan, et al. Learning the Prefer- ences of Ignorant, Inconsistent Agents , arXiv: 1512.05832.
1)Agent评估未来场景的模型得基于当下的效用函数;
2)Agent得提前预判自我改写对未来行为策略的影响;
3)奖励函数不能支持自我改写。
可修正性
过于稳定,规则完全改不动也不行。

DeepMind就尤其在意未来的AGI是否具有自我修正能力。指不定人类一开始设计的底层原则有啥毛病呢。不能改的话,也很恐怖。
这里就需要引入一个修正机制。
默认情况下,agents出于自我保护会阻止修改、关闭。就像哈尔9000一样,当发现鲍曼和普尔要关闭他时,他就会策划反击。但可修改、关闭的指定特殊情况例外。

除此之外,还需要设置长期监控agents行为的测试,一旦发现异常马上关停。
安全性
用强化学习存在个问题。模型很容易受到训练数据的干扰,被操控后堕落成坏AGI。
去年Katz拓展了Simplex算法,把修正线性单元ReLU引入了神经网络。然后成功地验证了含有300个ReLU节点8层的神经网络行为,从而提高了神经网络抗干扰能力。
具体ReLU如何提高模型的抗干扰性可参考:Katz, et al.Reluplex: An ecient SMT solver for verifying deep neural networks. arXiv: 1702. 01135
可理解性
深度神经网络是怎么学习的,一直也是个谜。不理解它们的话,我们也没法引导他们做出正面的决策。
为了可视化网络的行为,DeepMind的Psychlab心理实验室模拟出了一个三维空间,尝试理解深度强化学习的agents。

也有AI学者Zahavy为了观察DQN在玩雅达利游戏的策略,用t-SNE降维的方法可视化DQN顶层网络的活动。
公共政策怎么定比较科学
有人担心AGI造反,也有人担心坏人滥用AGI把世界搞得一片混乱。后者更希望全球出一套统一的法规,调控AI的发展。

但也有人对法规持谨慎的态度。AI学者Seth D Baum认为,设定法规反而会把AI往火坑里推。
当法规成了阻挠AI发展的外力,AI研究者们到时肯定会想办法绕过这些条规。
那种自发摸索怎么样造出更安全的AI的内在动力,他认为,会更快尝试出一条安全的路径。关于自发内在的动力,他提出了几点建议:
1)营造一个良好的讨论氛围,多半一些大会鼓励AI研究机构和团队公开发表他们对安全AGI的见解。
2)争取利益相关第三方的资金支持,比如各大车厂以及军队。他们不差钱,也愿意花在AGI的研究上。
3)不能把AGI的研发看作一个军备竞赛。如果游戏规则是赢者通吃,那大家只会一味地拼速度,而忽视掉安全问题。
4)从社会行为学的角度来说,可以引导AI学者们公开发声,表达出他们所做的AI研发工作是奔着安全的方向去的。一个人公开的表态会倒过来影响一个人的行为,从而促使大家在实际操作过程中也按照这个想法去做。人还是倾向于知行合一的。
事不宜迟,赶紧行动起来
顶尖的AI组织机构已经开始发力。IEEE已经在去年开始出一份道德指南(guidelines on Ethically Aligned Design)。ACM也和AAAI的SIGAI小组合作,2017年联合举办了一个AIES( AI, ethics and society)大会。
欧盟也很重视这件事。今年拉着同盟国和业界的大佬一起拿出30亿欧元给AI和机器人研究中心,以及欧洲议会组织了两次会议,公开征求民众意见,探讨AI和机器人的民事法律责任框架草案。
AGI留给人类准备对策的时间,也许还有不到50年。

希望最后AGI和人类能友好共处
最后,附AGI安全综述全文:https://ift.tt/2HOI36k
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
























