安妮 李根 发自 山景城 量子位 报道 | 公众号 QbitAI
今天凌晨,Google I/O 2018大会拉开帷幕。
开场一句Make good things together,然后就向全世界展示了AI将会带来的美好世界,2小时内,黑科技亮眼,情怀满分。
具体什么情况?量子位带你一文打尽。

开场
这次的核心串讲人还是Google CEO皮猜。
他说今年有7000人来到现场,见证AI带来的焕然新机,也会看到AI正在带来的巨大变革和机遇。
当然,Facebook事件当前,皮猜也谈到了AI和隐私、技术和价值观的看法。他认为技术更核心的是正能量,但在隐私和道德等层面,也需要谨慎前行,而Google对此深怀责任感。
比如在印度,Google的医疗AI正在进行视网膜筛查心脏病和糖尿病,可以解决医疗资源不公的问题。而同样还是AI加持,Gboard(谷歌输入法)能够让使用摩斯码设备进行交流的残障人士更好生活。

Google还把使用摩斯码设备进行交流的残障人士请到现场,于是会场掌声雷动,持续许久。
不过,这只是Google情怀开胃菜,新品新动作的正餐端上,每一个都藏着AI对于世界的热爱。
我们一款一款看。
首先介绍的是,AI对于Google几款核心产品的变革。
Gmail:脑补回复
可以更加智能化写邮件,运用机器学习可以在你键入时实时推荐"你可能会用"的短语,让你只要不断点击确认键就行。
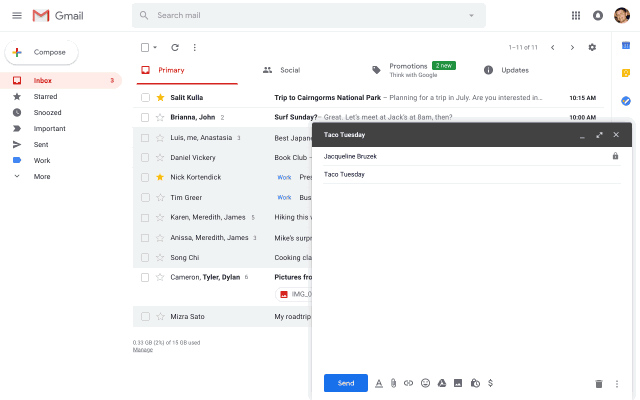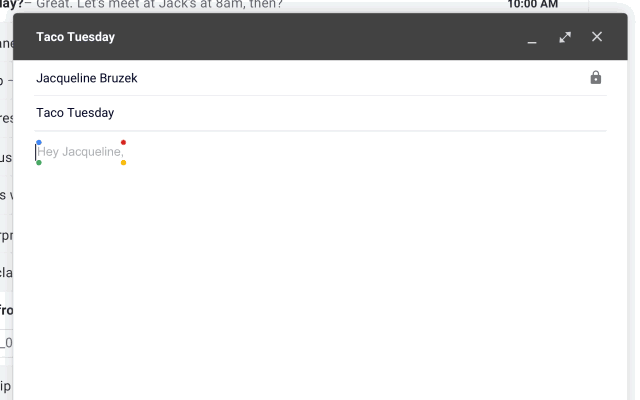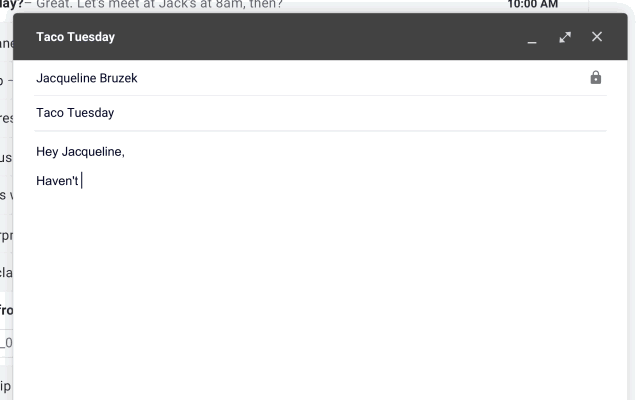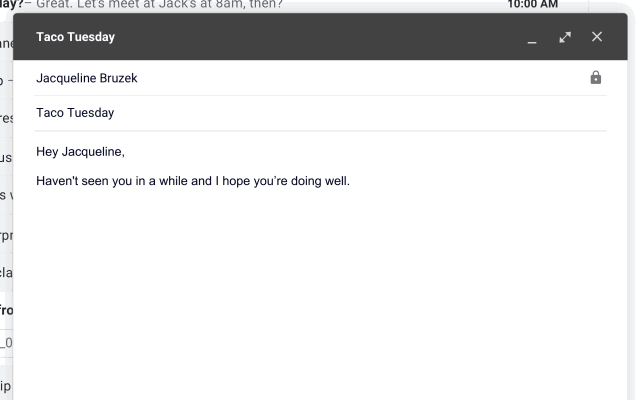
这个功能被称为"Smart Compose",5月末正式向全体用户上线。
Google Photos:智能P图
如今,每一天有超过50亿张的照片在Google相册中被查看。
而Google希望用AI带来的全新功能,让照片查看更简单。
一方面,识别和分享。可以帮你归类婚礼等活动照片,通过Smart Actions功能圈出好友更方便分享,以及把文件照片直接变成PDF扫描文件,让你更方便阅读。
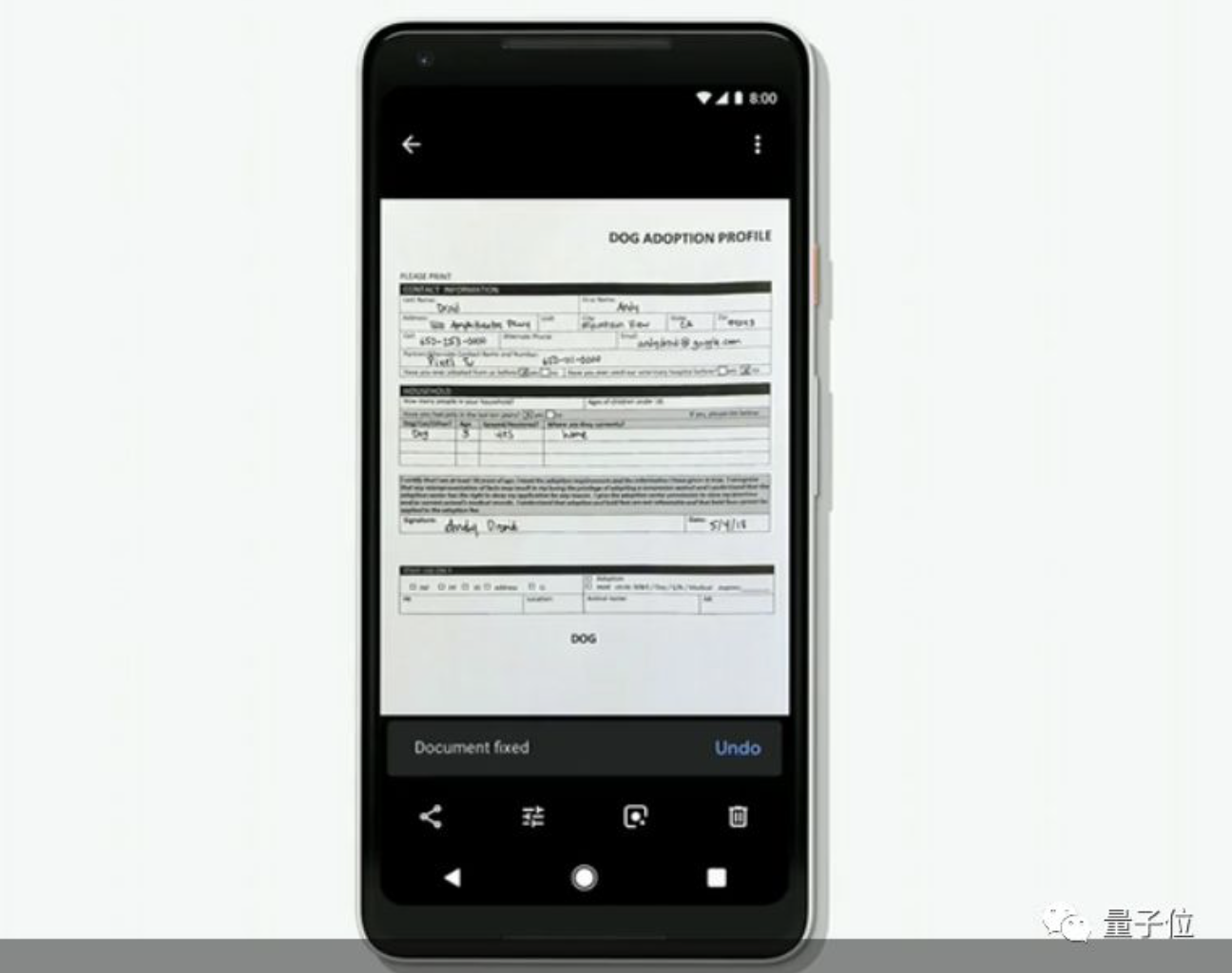
另一方面,智能P图。利用AI分割图像,不仅能修复过度曝光或曝光不足的照片,还可以对老照片\黑白照片进行色彩还原。

这自然不是一个轻轻松松的工作,也是计算力的霸气外露,所以皮猜顺便表示:这是Google使用了特殊定制设计的机器学习芯片的结果。
即TPU。
TPU 3.0:比上一代强悍8倍
现在正式推出TPU 3.0,相比去年发布的2.0版本,性能提升8倍,高达100 petaflops,而且由于芯片太强大,Google第一次引入液体冷却方法——对于希望为机器学习创建定制硬件的公司来说,散热越来越成为一个难题。

皮猜同时强调,强大的TPU是Google AI更多完美使用的关键。
但谁才是Google AI最核心的应用?Google助手。
Google助手打Call真假难辨
新版本的Google助手亮点不少。
首先是"声音",采用了DeepMind(在I/O上被cue不多见)的Wavenet技术,可以提供6种很自然的"人声",并且音色之完美,已经可以以假乱真。
其次是Google助手搭载量。
现在已经有5亿台设备接入了Google助手,支持30多种语言,进入了80多个国家和地区——但中国区域依然空白。
不过现场演示的第三方设备则来自中国,一台联想的带屏智能音箱,7月就会发售。
第三是Google助手最重要的应用设备——手机。
新版本更新后,用户就可以利用Google助手订外卖,不过是到店自取——这一点中国人民哪会大惊小怪。
值得一提的是,这其中也会打通Google助手+Google 地图。所以Google的思路再明显不过:让所有Google软硬件产品都有Google助手加持。
此外,Google助手将有更多视觉感知能力。
最后,最大惊喜来自Google助手的新能力:打Call!
比如打电话到美发沙龙。AI那声"嗯哼"笑翻全场。
比如你可以通过Google助手预约订座——没错,它会直接打电话到餐厅,然后与餐厅工作人员进行多轮对话,更恐怖的是,对面可能完全分不清到底是人还是AI。
现场演示也将本次I/O带入一个小高潮。
令人感慨的是,互联网时代的名句是"电脑后不知是人是狗",但AI降世,未来给你打电话的似乎也难辨是人还是AI。
当然,餐厅\服务组织也能用这个功能接听电话,可以省去不少人力成本。
(但求AI拨打的骚扰\营销电话晚一些到来……)
目前,这项功能还在继续开发中。
Google News:无死角式AI报道
下一个登场的是Google News。其更新可用个5字来形容:懂你,更懂你。
新推出的"For You"栏目将利用机器学习技术,更好了解用户行为,每次将为用户推荐5个可能感兴趣的故事。
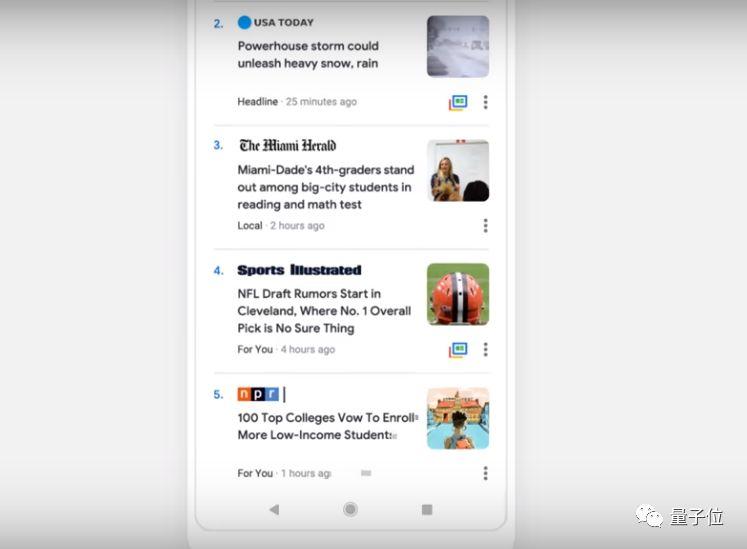
Google还推出一种全新的视觉格式叫做Newscasts,利用自然语言理解技术为用户推荐单一主题的文章和视频。汇集不同的新闻源,帮你找到最全面的信息。
若用户还想深入到一个特定话题,那么新推出的"Full Coverage"(全覆盖)功能可以帮你看到与这个事件相关的各种信息,包括不同来源的文章、视频、评论评论甚至相关的其他连锁信息。
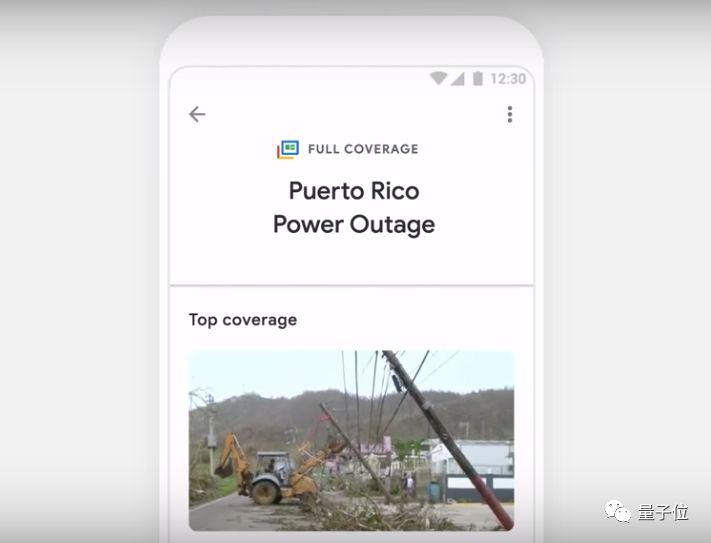
简单来说,GoogleAI学会了自己创造新闻专题,堪称360度无死角报道~
Android P:为电池增寿、防沉迷
Google News之后,下一代安卓系统来了,代号Android P。

不出所料,Android P中还是融入了AI技术。
那么,AI到底体现在了哪里?可以说相当有趣。
拯救手机没电一族,Google与DeepMind合作,正在研究自适应电池,用AI增加电池寿命。
AI将监控你手机的电池消耗情况,并将关闭你暂时没有接触过的应用程序。"它还会根据你的习惯调整你手机的亮度,Google数据显示,Android P系统在唤醒应用程序时,平均会减少30%的CPU使用量。

此外,Android P还带来了全新的交互形式,提出了"Action"(动作)和"Slices"(切片)的新概念。现在,在Android P的搜索可以做到事半功倍,比如当你想找到Lyft应用时,可以直接显示应用程序,而无需在不同的应用程序之间进行切换。
用过安卓的你肯定记得之前系统下像三颗纽扣版的导航,在Android P中,这样的操作系统界面将和我们彻底说再见。
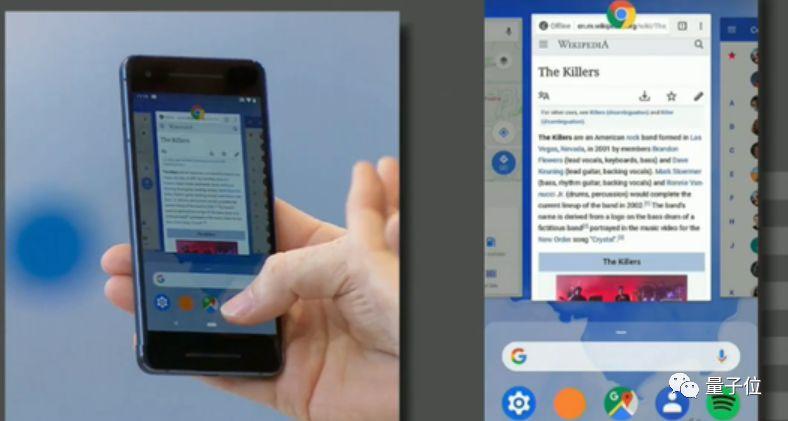
Android P的交互界面和iPhone X类似,通过手势进入不同的界面和功能。拥有一个全新样貌的指示板,显示你的玩手机的"活跃指数"。在App上耗时如何、解锁几次、收到多少通知……你的私人防手机沉迷小助手已经上线。
Android P将于今年夏天晚些时候面市,但今天的公开测试版可以从即将到来的1加6、已经到来的小米MIX 2S、OPPO R15 Pro、Vivo X21及Google、Essential、索尼、诺基亚等几款智能手机中抢先体验一把。
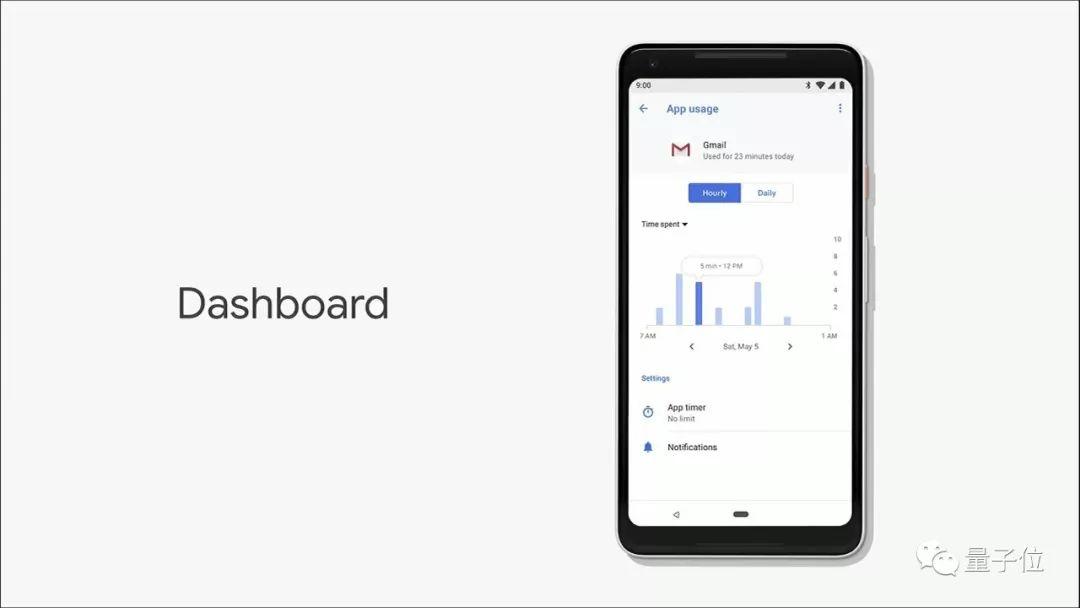
Dashboard:解救手机焦虑症
Android P中还有重点推出的Dashboard功能。
Google想通过这个功能,让用户能更"健康"使用智能手机,关注所谓"数字化健康"问题。
主讲人Sameer说,因为智能手机太方便,以致于休假时都要被不断碎片化打断。
所以在安卓 P 版本中,首先会推出Dashboard,可以让你更好知晓:智能手机的时间都去哪儿了。
你可以查看每个App的应用时间,以及它们到底给你发送了多少通知。
同时,还能设置刷YouTube和Twitter的时长,到时间就变灰。Wind Down。

最后,现在还推出了一个名为"Shush"("嘘")的新玩法,只要把手机背面向上扣在桌上,手机就会自动进入"勿扰"模式。

这部分演示时,现场多次响起了共鸣掌声,当然也有一些情怀的因素,毕竟在更多App开发者想方设法留住、消磨你更多时间的时候,Google却希望你能在数字化时代同样健康生活,而且Google也强调:数字福祉,将成Google未来的长期主题。
更关键的是,这种福利这次也与中国用户有关。即将推出的安卓 P Beta测试版,全球7家手机厂商中,中国真真占据"半壁江山":小米、一加、OPPO和vivo都成为了首批合作机型。
Google地图:路痴福音
接下来登场的是Google地图,毫无疑问依然由AI驱动。
先介绍了最近进展,比如绘制并覆盖了220个国家和地区,累计让10亿用户通过Google地图在全球各地旅行。
但是现在,AI驱动之后,Google可以直接使用AI和卫星图像结合的方式,将更多商户和新地址添加到地图中,这对于很多发展中国家都很重要。
所以AI也会进一步带来地图使用的变革,之前是告诉你"在哪儿",未来可以更多帮助你"去那儿"。

可以直接通过Google地图搜索"附近营业的串店",总之就是帮助你发现和体验身边的世界。
当然,AI也会带来个性化推荐,通过大数据挖掘分析(比如你的音乐喜好、常去路线)等给你推荐美食店之类的,该功能可以说是"Google想让你长肉"。
然而作为Google这样的企业,一方面思考让用户更方便,另一方面也尝试让商家效率更高,比如通过全网数据挖掘,更快更新中小企业信息、营业时间、服务方式等,节约这些组织的时间。
不过Google地图的AI加持,还没完。
相机:打通虚拟世界和现实世界
利用AI,Google地图和相机还实现了打通。
直接与Google街景结合,打通虚拟和现实,堪称路痴福利,把AR应用到了相机中,打开相机,就能AR指方向——你妈再也不用担心你走错了。
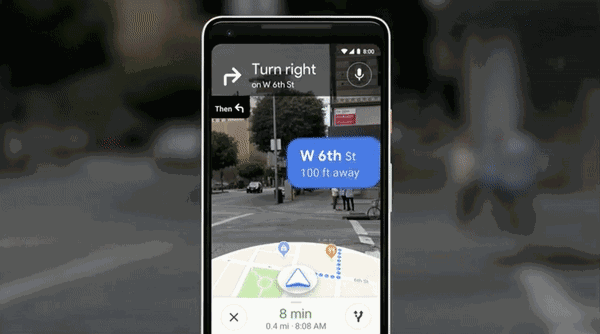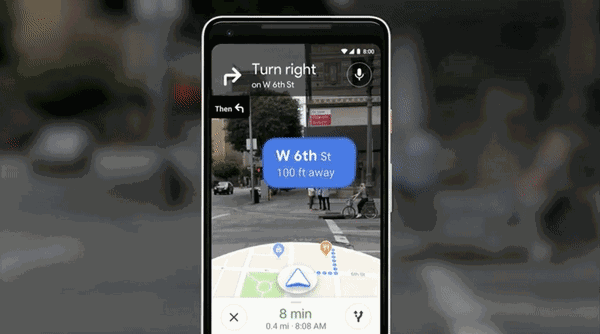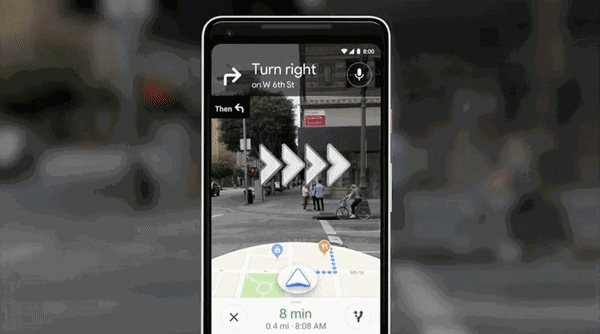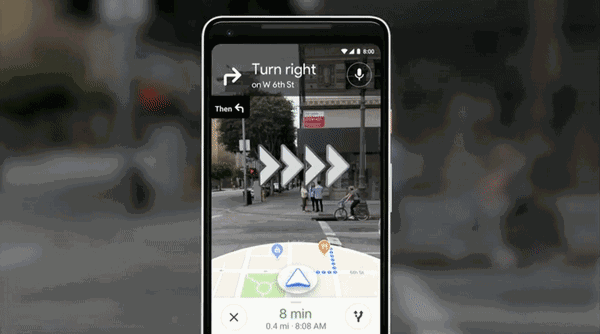
类似应用之前最核心的是Google Lens,一款拍照搜索的App。
现在,拍照翻译(拍菜单)、拍照购物(类似拍立淘),以及拍图识别文字(类似OCR)都会在数周后发布的新版本中上线。
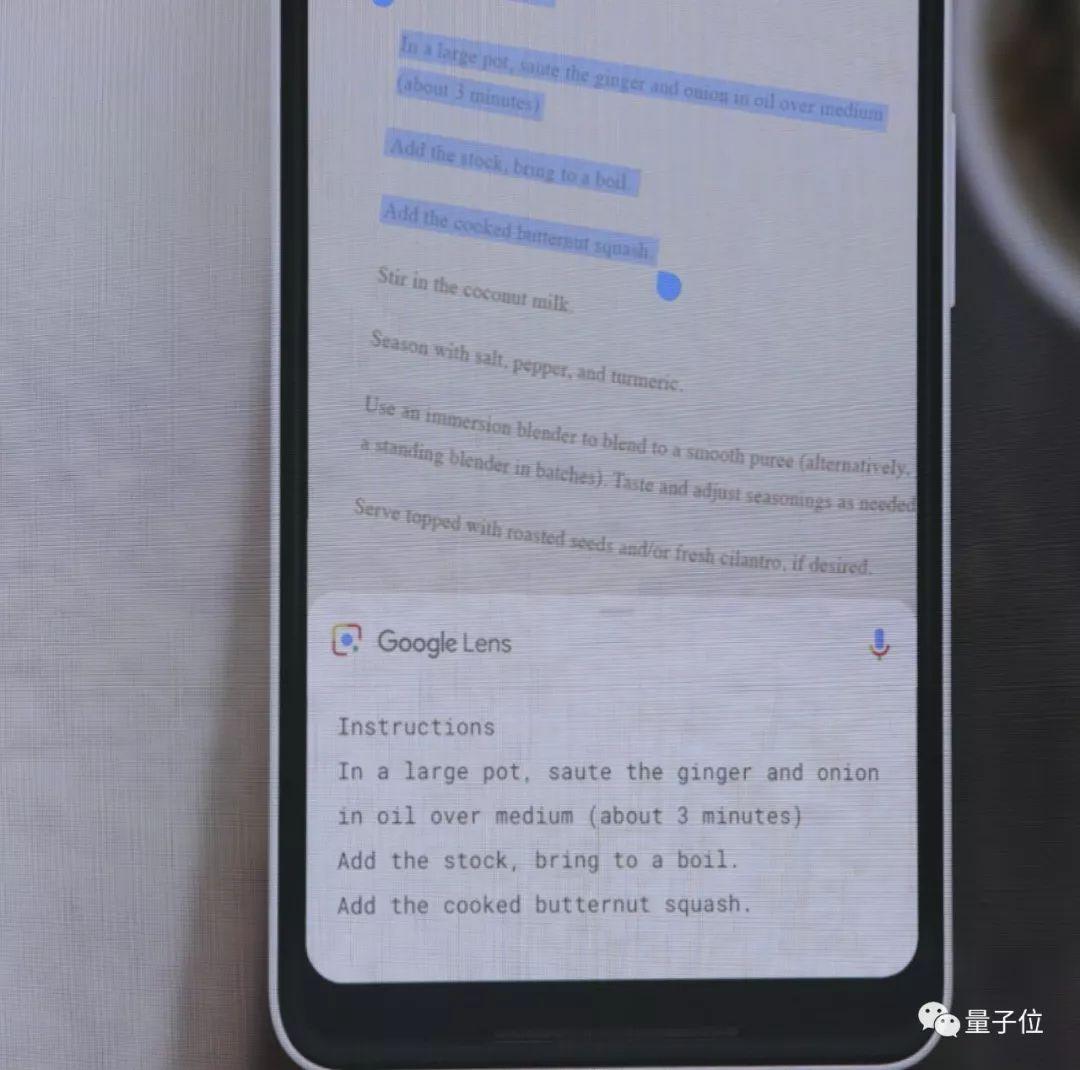
而且!目前只在Google Pixel手机中的Lens,下一步将进入更多安卓智能机中,比如小米、一加、TCL。
总之,Google利用AI技术,带来了虚拟世界和现实世界的新连接方式,并且能够帮助解决更多现实问题。
OMT:Waymo进展
最后,今天还有"乱入"的Waymo。
作为同属Alphabet的Google兄弟公司,Waymo首次在I/O大会上登台介绍进展颇有其他意味。
Waymo CEO John Krafcik没说啥新进展。
首先,今年晚些时候,会在凤凰城地区推出Waymo无人驾驶出租车。"Waymo不是在造一辆更好的车,而是建设一个更好的司机。"
其次,Waymo接下来的路,还将是合作共赢模式。Waymo打算与许多不同的公司合作,而不会仅仅局限于某一家车厂。
跟开发者相关的是,目前机器学习技术在Waymo无人车设计中挑起大梁,将检测行人的错误率降低到之前技术的百分之一,甚至连穿着恐龙服饰的人都能识别出来了。

此外,Krafcik表示,深度学习技术是帮助Waymo走上L5级自动驾驶的重中之重,目前,在无人车的感知和预测方面起到了重要作用。还展示了如何应付下雪天。

最后,Krafcik交出了一份Waymo无人车测试成绩单:
迄今为止,Waymo已经在公共道路上行驶了超过600万英里,在模拟中行驶了超过50亿英里。目前,Waymo的模拟还没有停止,还在持续测试恶劣天气中的无人车表现。目前,每天接受测试的Waymo无人车,大约为2.5万辆。
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态