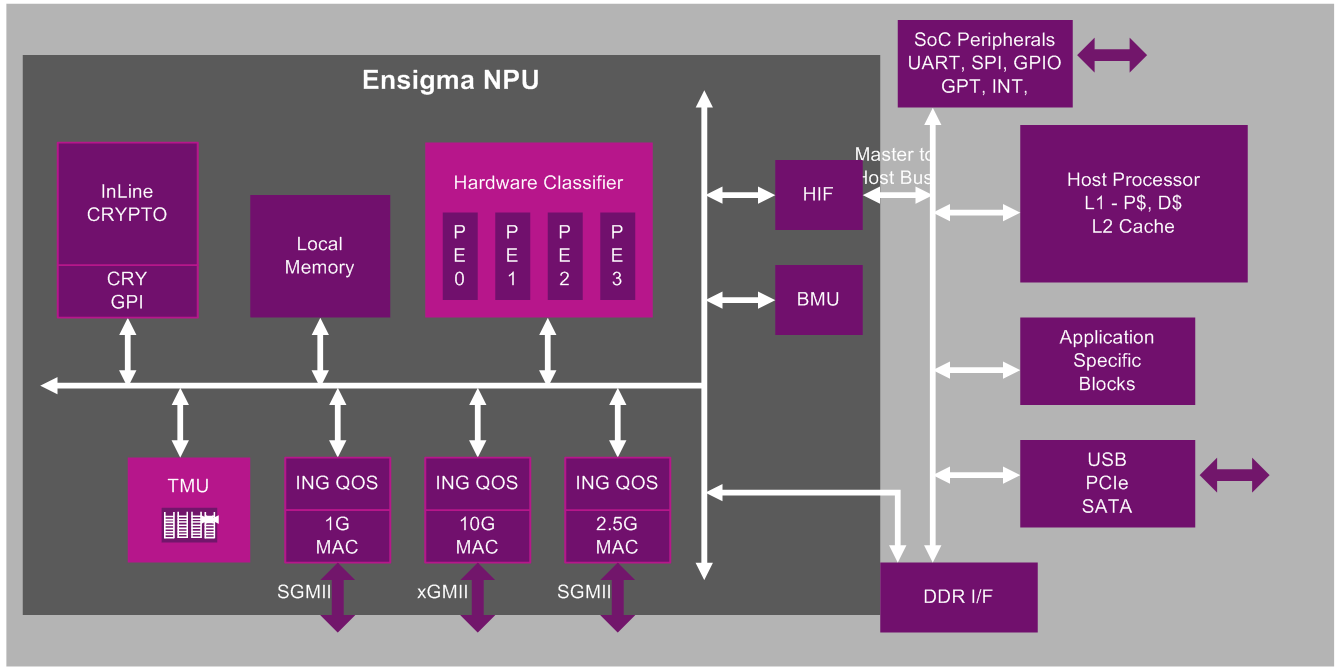
| 5 月 3 日,智能芯片公司寒武纪科技在上海举办了 2018 产品发布会。会上,寒武纪正式发布了多个最新一代终端 IP 产品——采用 7nm 工艺的终端芯片 Cambricon 1M、首款云端智能芯片 MLU100 及搭载了 MLU100 的云端智能处理计算卡。 在人工智能技术的发展过程中,神经网络正不断迈向更深、更复杂的方向,而硬件则正朝着机器学习任务处理专用的道路前进。目前,国内已出现十余家人工智能芯片公司,而寒武纪是其中的佼佼者。作为全球唯一一家 AI 芯片独角兽,寒武纪于 2016 年诞生于中国科学院计算技术研究所,并率先推出了商用化的深度学习专用处理器 NPU(神经网络处理器)。 其实,寒武纪科技的产品早已进入普通用户的手中。去年 10 月,华为发布了搭载全球首款「人工智能处理器」麒麟 970 的手机 Mate 10 系列(以及其后发布的华为 P20、荣耀 V10 系列等),其芯片架构中就包含了寒武纪的 Cambricon-1A 神经网络处理器。1A 也由此成为了全球首个成功商用的深度学习处理器 IP 产品。 寒武纪的智能处理器主要针对于人工智能领域计算机视觉、语音识别等方面的任务,面向智能手机、安防监控、可穿戴设备、无人机和智能驾驶等各类应用。据称,其专为神经网络任务优化的架构可以使其达到传统四核 CPU25 倍以上的性能。 与此前仅面向终端设备的芯片 IP 不同,本次发布会上,寒武纪推出的芯片不仅性能更强大,而且还出现了面向云端服务器等专业应用场景的产品。 第三代终端芯片:寒武纪 1M 首先是终端处理器部分。今天发布的寒武纪 1M 是这家公司的第三代机器学习专用芯片,其性能超越此前广泛使用的寒武纪 1A 十倍。去年 11 月 6 日,寒武纪在北京举行了公司成立以来的首场发布会,陈天石在会上披露了 1M 处理器的发展计划。 在本次发布会上,寒武纪 1M 处理器的具体参数终于展示在人们的眼前。1M 使用 TSMC 7nm 工艺生产,其 8 位运算效能比达 5Tops/watt(每瓦 5 万亿次运算)。寒武纪提供了三种尺寸的处理器内核(2Tops/4Tops/8Tops)以满足不同场景下不同量级智能处理的需求,寒武纪称,用户还可以通过多核互联进一步提高处理效能。 寒武纪 1M 处理器延续了前两代 IP 产品(1H/1A)的完备性,可支持 CNN、RNN、SOM 等多种深度学习模型,此次又进一步支持了 SVM、k-NN、k-Means、决策树等经典机器学习算法的加速。这款芯片支持帮助终端设备进行本地训练,可为视觉、语音、自然语言处理等任务提供高效计算平台。「这意味着使用 1M 的设备可以根据用户行为对应用进行个性化定制,」陈天石表示。「本地训练同时也解决了用户数据隐私的问题。它是全球第一款支持本地机器学习训练的智能处理器产品。」据悉,该产品可应用于智能手机、智能音箱、摄像头、自动驾驶等不同领域。 首款云端智能芯片:MLU 100 在去年 11 月份的发布会上,陈天石展示了服务器级 AI 处理器 MLU 系列的发展计划,寒武纪希望将自己的产品从神经网络加速拓展到机器学习,以及更多任务中。本次发布的又一大重点就是首次亮相的 Cambricon MLU 100 云端 AI 芯片,以及以此为基础的云端智能处理计算卡。「在三年前,我们就开始了两颗测试芯片的研发了。我们时刻准备着将自己的产品放入云端。」陈天石表示。今天推出的产品正是寒武纪稳步推进的成果。 
MLU100 采用寒武纪最新的 MLUv01 架构和 TSMC 16nm 工艺,可工作在平衡模式(主频 1Ghz)和高性能模式(1.3GHz)主频下,等效理论峰值速度则分别可以达到 128 万亿次定点运算/166.4 万亿次定点运算,而其功耗为 80w/110w。与寒武纪系列的终端处理器相同,MLU100 云端芯片具有很高的通用性,可支持各类深度学习和常用机器学习算法。可满足计算机视觉、语音、自然语言处理和数据挖掘等多种云处理任务。搭载这款芯片的板卡使用了 PCIe 接口。 在发布会上,寒武纪的合作伙伴们展示了基于寒武纪芯片的部分应用方案。其中联想推出了基于 Cambricon MLU100 的服务器 ThinkSystem SR650。该产品为 2U2 路机架式规格,支持两个 MLU100 智能处理器计算卡。这款服务器打破了 37 项服务器基准测试的世界纪录。 中科曙光也在发布会上推出了基于 Cambricon MLU100 的服务器产品系列「PHANERON」。这款服务器可支持 2-10 块寒武纪 MLU 处理卡,面向多种智能应用任务。其中 PHANERON-10 集成了 10 块寒武纪人工智能处理单元,可以为人工智能训练应用提供 832T 半精度浮点运算能力,在推理时提供 1.66P 整数运算能力。中科曙光表示,新一代服务器可以在典型场景下将能效提升 30 倍以上。 科大讯飞也在发布会上披露了与寒武纪的深度合作研发项目。 正如 MLU 的系列命名所示,寒武纪希望把旗下芯片的应用范围由神经网络(Neural network)扩展到机器学习(Machine Learning)的加速任务上。由于 IP 授权的方式利润空间有限,进军云端市场或许是寒武纪作为新一代芯片公司发展的必然道路。 寒武纪表示,旗下的终端和云端产品均原生支持寒武纪 NeuWare 软件工具链,可以方便用户进行智能应用的开发、迁移和调优。陈天石表示,寒武纪科技创立的初衷就是要让全世界都能用上智能处理器。寒武纪本次提出了「端云协作」的理念,这次发布的 MLU100 芯片可以和此前寒武纪 1A/1H/1M 系列终端处理器进行适配,协同完成复杂的智能处理任务。 至此,寒武纪已经形成了覆盖智能终端设备、自动驾驶以及云端服务器的 AI 智能芯片 IP 产品线。「寒武纪未来计划发布自己的编程语言,」陈天石说道,「我们希望自己的合作伙伴能够基于这套软件系统发布自己的产品。」 机器之心专访了寒武纪科技的创始人和 CEO 陈天石,他就一些我们感兴趣的话题进行了解答。 机器之心:相对市场上已有的同类芯片,新的产品(MLU100)在设计上具备哪些优势? 陈天石:MLU100 是寒武纪公司长期积累的成果,基于 Cambricon 指令集,在机器学习领域适用面广。而且得益于寒武纪在微结构方面的创新,达到了最高每秒 166.4 万亿次定点运算的峰值。 机器之心:针对新一代芯片,寒武纪是否会推出相关软件 API,和完整的解决方案? 陈天石:寒武纪公司从 2016 年起,逐步推出了寒武纪 NeuWare 软件工具链,实现对 tensorflow、caffe 和 mxnet 的 API 兼容,并同时提供了寒武纪专门的高性库,可以方便地进行智能应用的开发,迁移和调优。目前,由于寒武纪在终端的广泛应用,已经有不少客户在寒武纪 NeuWare 之上构建了他们的应用。 机器之心:有关产品定位的问题,您认为新的芯片会对目前已有的市场产生冲击,还是会开拓出新的市场?直接对标的同类产品是什么? 陈天石:寒武纪相信智能是一个快速增长的市场,我们愿意和全世界的同行实现合作共赢。 机器之心:寒武纪在 2018 年选择了「由端入云」的发展方向,是出于什么样的思考?以及如何看待云端计算的发展趋势? 陈天石:端侧的智能处理是非常重要的,因为端可以最快速的响应用户的需求,能以非常低的功耗、非常低的成本、非常小的延迟,帮助用户理解图像、视频、语音和文本。但是,云侧的智能处理可以把很多端的信息汇聚在一起。比如,在一个城市中有大量的摄像头,如果想要知道一个特定的物体在多个摄像头间的运动轨迹,就需要在云侧进行智能处理。 另外,终端的数据量有限,只能根据单个用户的数据对机器学习模型进行微调。而云可以看到大量用户的数据。因此,云端的智能处理在数据方面有其不可替代的巨大优势,可以利用海量数据,训练出非常强大的模型。 机器之心:寒武纪的产品线更新战略是什么样的,多久推出一代新的芯片? 陈天石:寒武纪公司有着一支高效、执行力强的研发队伍,以及一个稳定的技术路线图,会以较快的速度不断推出新的产品满足市场的需求。寒武纪 2017 年 11 月发布终端 IP 产品 1A 和 1H 的时候,就预告了今年 5 月份的新 IP 产品 1M,和云端 MLU100 芯片。 机器之心:我们能否期待下一代消费级 NPU 的消息? 陈天石:我们通常不称自己是 NPU,因为 Neural Processing Unit 把应用面限定在神经网络上。事实上,寒武纪做的是 MLU(Machine Learning Unit),各种机器学习算法(包括神经网络深度学习,也包括多种传统机器学习算法)都能很好地支持。在终端,寒武纪这次发布了 IP 产品 1M,前所未有的具备本地的训练能力,这给终端用户个性化、定制化、适配化的智能服务提供了应借鉴支撑。1M 的 PPA 也有很大的进步,可以达到 5Tops/W。 机器之心:寒武纪的新一代芯片(MLU 100)在推出之后将与哪些公司展开合作? 陈天石:这次发布会上,曙光和联想都推出了基于寒武纪的云服务器新产品。我们也在深入同各大云计算企业深入合作。 ]]> 原文: https://ift.tt/2jruZ8v | 






 MLPerf 在模拟之前的一些尝试,比如 SPEC(标准性能评估组织)。「SPEC 基准加速了通用计算方面的进步。SPEC 于 1988 年由多个计算公司联合成立。接下来的 15 年中 CPU 性能提升 1.6X/年。MLPerf 将之前基准的最佳实践结合起来:SPEC 使用的一套程序;SORT 的一个部门来做性能对比,另一个部门负责创新;DeepBench 覆盖产品中的软件部署;DAWNBench 的 time-to-accuracy 度量。」MLPerf 称。
MLPerf 在模拟之前的一些尝试,比如 SPEC(标准性能评估组织)。「SPEC 基准加速了通用计算方面的进步。SPEC 于 1988 年由多个计算公司联合成立。接下来的 15 年中 CPU 性能提升 1.6X/年。MLPerf 将之前基准的最佳实践结合起来:SPEC 使用的一套程序;SORT 的一个部门来做性能对比,另一个部门负责创新;DeepBench 覆盖产品中的软件部署;DAWNBench 的 time-to-accuracy 度量。」MLPerf 称。






