夏乙 编译整理量子位 出品 | 公众号 QbitAI题图来自Kaggle blog
从2014年诞生至今,生成对抗网络(GAN)始终广受关注,已经出现了200多种有名有姓的变体。
这项"造假神技"的创作范围,已经从最初的手写数字和几百像素小渣图,拓展到了壁纸级高清照片、明星脸,甚至艺术画作。
心痒难耐想赶快入门?
通过自己动手、探索模型代码来学习,当然是坠吼的~如果用简单易上手的Keras框架,那就更赞了。
一位GitHub群众eriklindernoren就发布了17种GAN的Keras实现,得到Keras亲爸爸François Chollet在Twitter上的热情推荐。
干货往下看:
eriklindernoren/Keras-GAN
AC-GAN
带辅助分类器的GAN,全称Auxiliary Classifier GAN。

在这类GAN变体中,生成器生成的每张图像,都带有一个类别标签,鉴别器也会同时针对来源和类别标签给出两个概率分布。
论文中描述的模型,可以生成符合1000个ImageNet类别的128×128图像。
code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/acgan/acgan.py
paper:
Conditional Image Synthesis With Auxiliary Classifier GANs
Augustus Odena, Christopher Olah, Jonathon Shlens
[1610.09585] Conditional Image Synthesis With Auxiliary Classifier GANs
Adversarial Autoencoder
这种模型简称AAE,是一种概率性自编码器,运用GAN,通过将自编码器的隐藏编码向量和任意先验分布进行匹配来进行变分推断,可以用于半监督分类、分离图像的风格和内容、无监督聚类、降维、数据可视化等方面。
在论文中,研究人员给出了用MNIST和多伦多人脸数据集 (TFD)训练的模型所生成的样本。

code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/aae/adversarial_autoencoder.py
paper:
Adversarial Autoencoders
Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, Brendan Frey
[1511.05644] Adversarial Autoencoders
BiGAN
全称Bidirectional GAN,也就是双向GAN。这种变体能学习反向的映射,也就是将数据投射回隐藏空间。
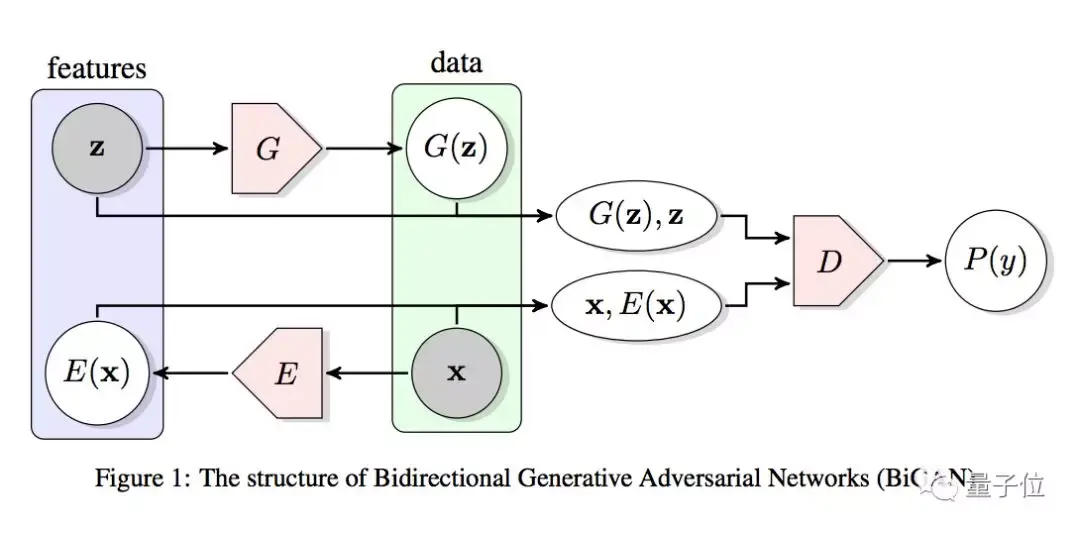
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/bigan/bigan.py
Paper:
Adversarial Feature Learning
Jeff Donahue, Philipp Krähenbühl, Trevor Darrell
[1605.09782] Adversarial Feature Learning
BGAN
虽然简称和上一类变体只差个i,但这两种GAN完全不同。BGAN的全称是boundary-seeking GAN。
原版GAN不适用于离散数据,而BGAN用来自鉴别器的估计差异度量来计算生成样本的重要性权重,为训练生成器来提供策略梯度,因此可以用离散数据进行训练。
BGAN里生成样本的重要性权重和鉴别器的判定边界紧密相关,因此叫做"寻找边界的GAN"。

Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/bgan/bgan.py
Paper:
Boundary-Seeking Generative Adversarial Networks
R Devon Hjelm, Athul Paul Jacob, Tong Che, Adam Trischler, Kyunghyun Cho, Yoshua Bengio
[1702.08431] Boundary-Seeking Generative Adversarial Networks
CC-GAN
这种模型能用半监督学习的方法,修补图像上缺失的部分。
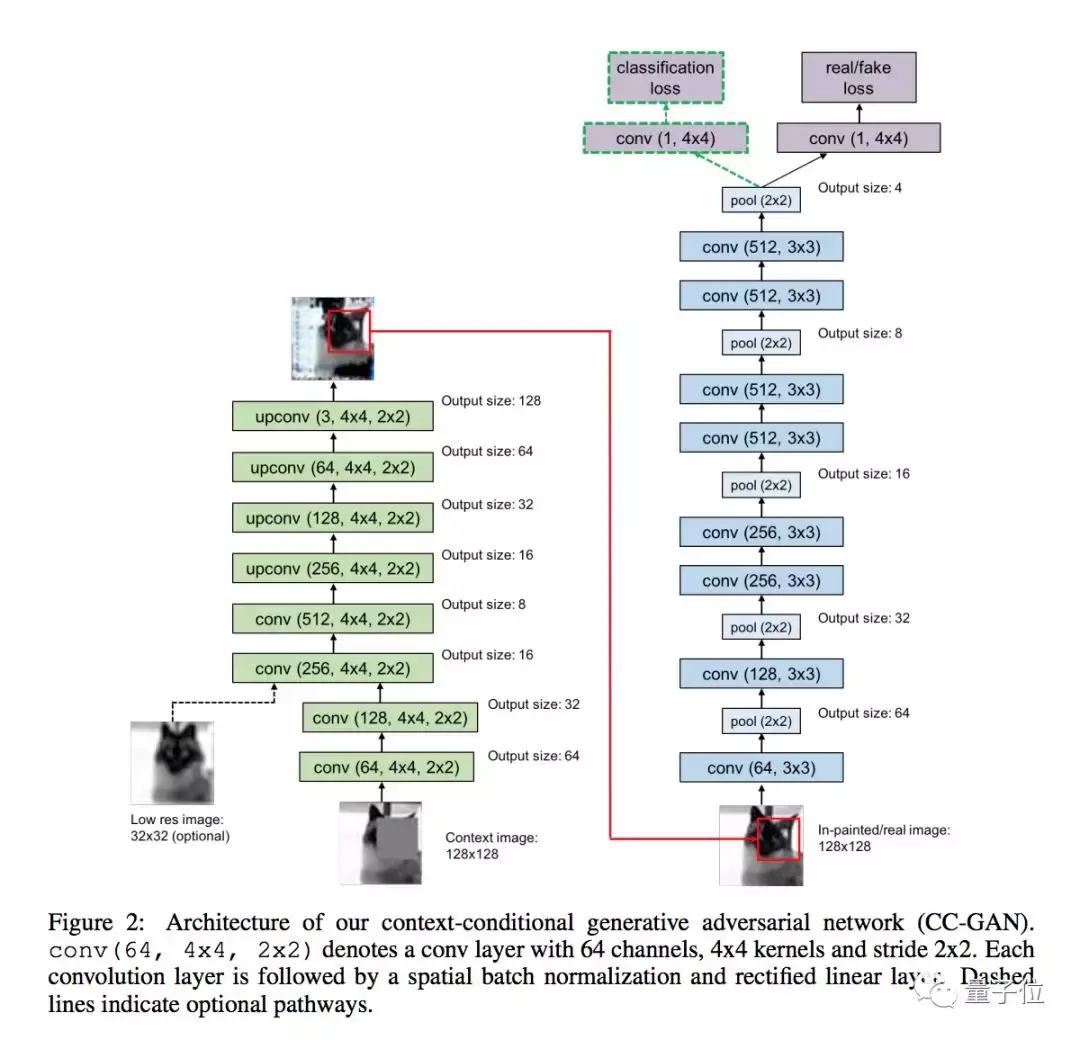

Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/ccgan/ccgan.py
Paper:
Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks
Emily Denton, Sam Gross, Rob Fergus
[1611.06430] Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks
CGAN
条件式生成对抗网络,也就是conditional GAN,其中的生成器和鉴别器都以某种外部信息为条件,比如类别标签或者其他形式的数据。
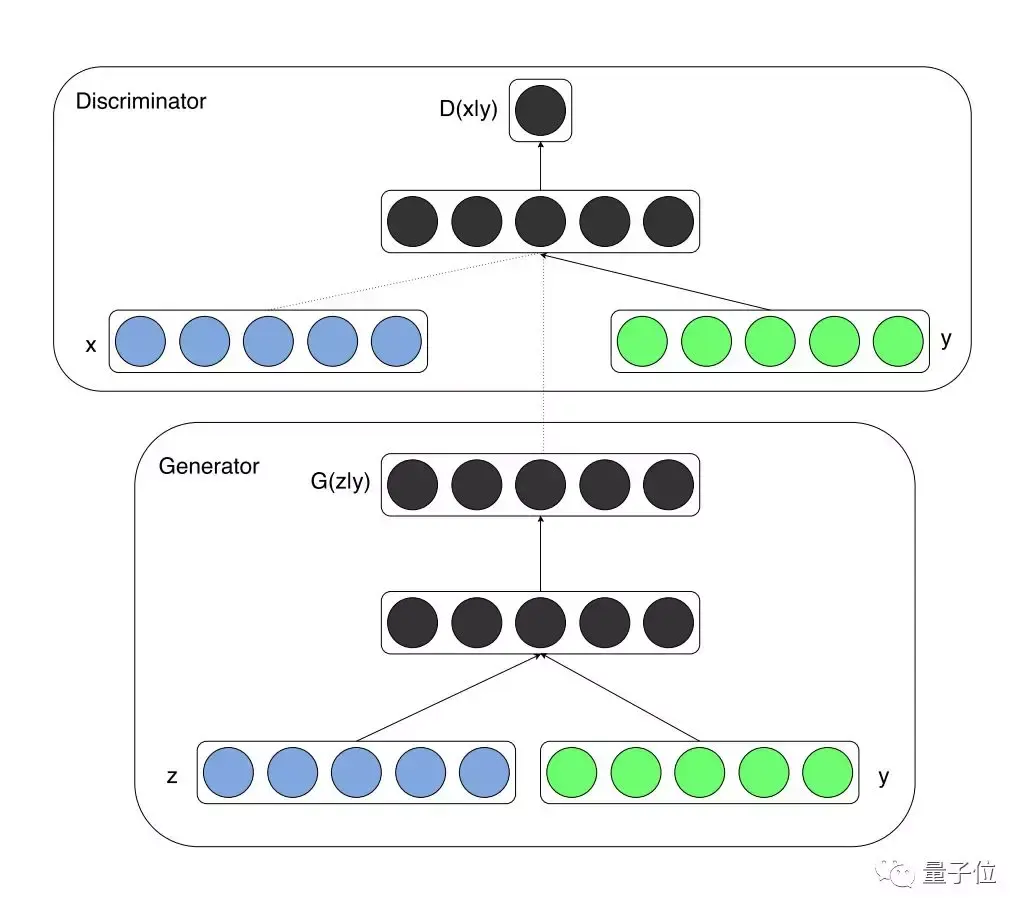
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/cgan/cgan.py
Paper:
Conditional Generative Adversarial Nets
Mehdi Mirza, Simon Osindero
[1411.1784] Conditional Generative Adversarial Nets
Context Encoder
这是一个修补图像的卷积神经网络(CNN),能根据周围像素来生成图像上任意区域的内容。

Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/context_encoder/context_encoder.py
Paper:
Context Encoders: Feature Learning by Inpainting
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, Alexei A. Efros
Feature Learning by Inpainting
CoGAN
这类变体全名叫coupled GANs,也就是耦合对抗生成网络,其中包含一对GAN,将两个生成模型前几层、两个辨别模型最后几层的权重分别绑定起来,能学习多个域的图像的联合分布。
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/cogan/cogan.py
Paper:
Coupled Generative Adversarial Networks
Ming-Yu Liu, Oncel Tuzel
[1606.07536] Coupled Generative Adversarial Networks
CycleGAN
这个模型是加州大学伯克利分校的一项研究成果,可以在没有成对训练数据的情况下,实现图像风格的转换。
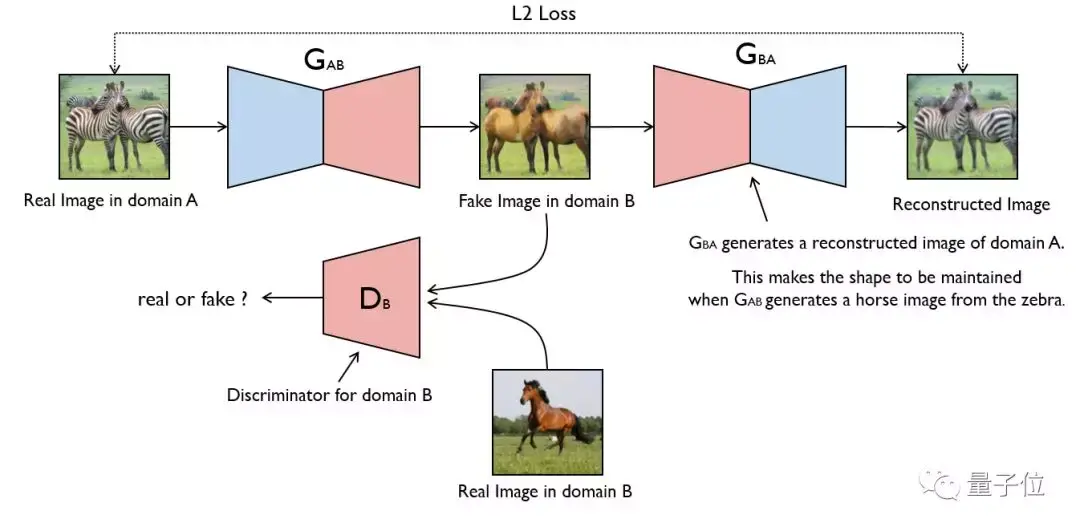
这些例子,你大概不陌生:

Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/cyclegan/cyclegan.py
Paper:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
[1703.10593] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
论文原作者开源了Torch和PyTorch的实现代码,详情见项目主页:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
DCGAN
深度卷积生成对抗网络模型是作为无监督学习的一种方法而提出的,GAN在其中是最大似然率技术的一种替代。

Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/dcgan/dcgan.py
Paper:
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, Soumith Chintala
[1511.06434] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
DualGAN
这种变体能够用两组不同域的无标签图像来训练图像翻译器,架构中的主要GAN学习将图像从域U翻译到域V,而它的对偶GAN学习一个相反的过程,形成一个闭环。
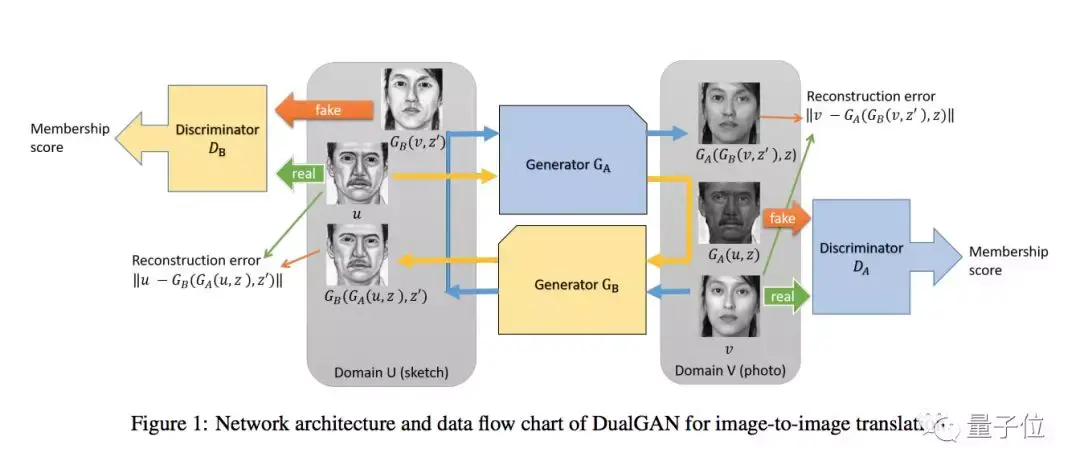
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/dualgan/dualgan.py
Paper:
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
Zili Yi, Hao Zhang, Ping Tan, Minglun Gong
Unsupervised Dual Learning for Image-to-Image Translation
GAN
对,就是Ian Goodfellow那个原版GAN。

Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/gan/gan.py
Paper:
Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
[1406.2661] Generative Adversarial Networks
InfoGAN
这个变体是GAN的信息论扩展(information-theoretic extension),能完全无监督地分别学会不同表示。比如在MNIST数据集上,InfoGAN成功地分别学会了书写风格和数字的形状。
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/infogan/infogan.py
Paper:
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, Pieter Abbeel
Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
LSGAN
最小平方GAN(Least Squares GAN)的提出,是为了解决GAN无监督学习训练中梯度消失的问题,在鉴别器上使用了最小平方损失函数。
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/lsgan/lsgan.py
Paper:
Least Squares Generative Adversarial Networks
Xudong Mao, Qing Li, Haoran Xie, Raymond Y.K. Lau, Zhen Wang, Stephen Paul Smolley
[1611.04076] Least Squares Generative Adversarial Networks
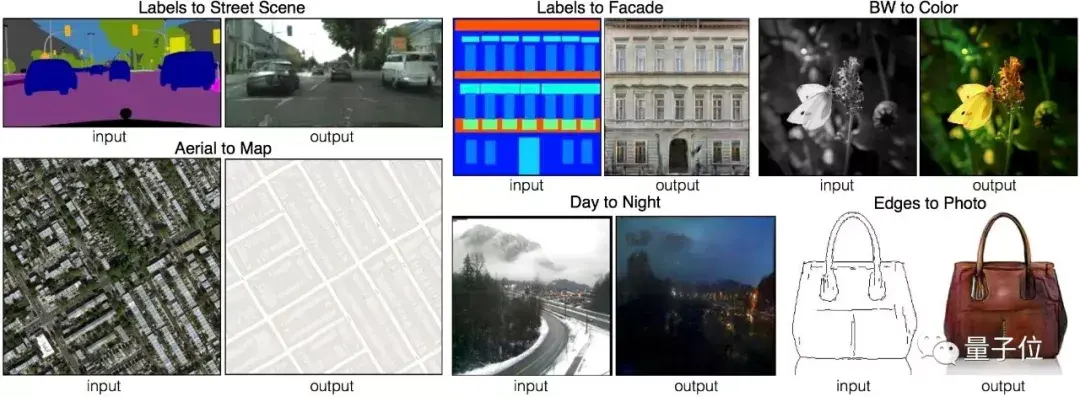
Pix2Pix
这个模型大家应该相当熟悉了。它和CycleGAN出自同一个伯克利团队,是CGAN的一个应用案例,以整张图像作为CGAN中的条件。
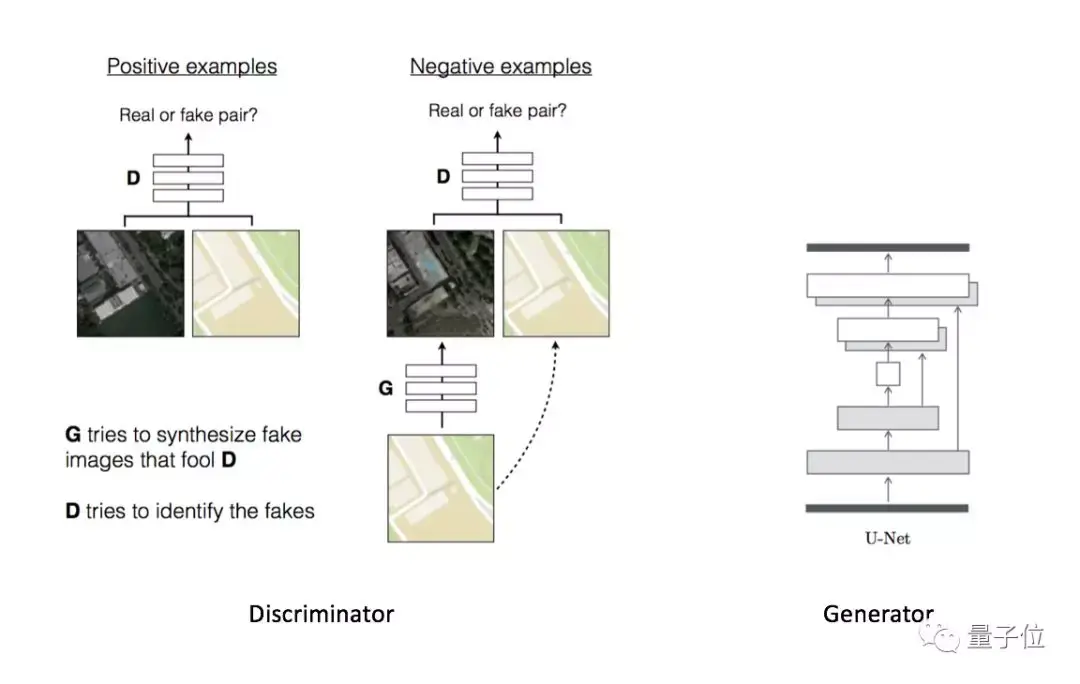
在它基础上,衍生出了各种上色Demo,波及猫、人脸、房子、包包、漫画等各类物品,甚至还有人用它来去除(爱情动作片中的)马赛克。
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/pix2pix/pix2pix.py
Paper:
Image-to-Image Translation with Conditional Adversarial Networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
[1611.07004] Image-to-Image Translation with Conditional Adversarial Networks
Pix2Pix目前有开源的Torch、PyTorch、TensorFlow、Chainer、Keras模型,详情见项目主页:
Image-to-Image Translation with Conditional Adversarial Networks
SGAN
这个变体的全称非常直白:半监督(Semi-Supervised)生成对抗网络。它通过强制让辨别器输出类别标签,实现了GAN在半监督环境下的训练。
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/sgan/sgan.py
Paper:
Semi-Supervised Learning with Generative Adversarial Networks
Augustus Odena
[1606.01583] Semi-Supervised Learning with Generative Adversarial Networks
WGAN
这种变体全称Wasserstein GAN,在学习分布上使用了Wasserstein距离,也叫Earth-Mover距离。新模型提高了学习的稳定性,消除了模型崩溃等问题,并给出了在debug或搜索超参数时有参考意义的学习曲线。
本文所介绍repo中的WGAN实现,使用了DCGAN的生成器和辨别器。
Code:
https://github.com/eriklindernoren/Keras-GAN/blob/master/wgan/wgan.py
Paper:
Wasserstein GAN
Martin Arjovsky, Soumith Chintala, Léon Bottou
[1701.07875] Wasserstein GAN
最后补充一点,作者为了让没有GPU的人也能测试这些实现,比较倾向于使用密集层(dense layer),只要在模型中能得出合理的结果,就不会去用卷积层。
— 完 —
欢迎大家关注我们的专栏:量子位 - 知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复"招聘"两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态